Care-Arbeit in Österreich
Von Lara Schimpf und Aylin Yilmaz
Who cares?
Warum Österreichs Haushalte hinterherhinken und uns das kümmern sollte
Nach einem langen Arbeitstag wird der Mann strahlend von seiner Frau begrüßt. Das Haus ist geputzt, die Kinder umsorgt und das Essen steht am Tisch. Was stark an die Rollenbilder der 50er erinnert, wird auf Tiktok-Accounts von sogenannten „Stay-at-Home Girlfriends“ (Partnerinnen, die zu Hause bleiben) als Privileg gefeiert. Ein Privileg, das ohne finanzielle Zukunftsvorsorge für problematische Abhängigkeitsverhältnisse sorgen kann. Um sich der Dependenzfalle zu entziehen, muss in den meisten Fällen doch eines her: Arbeit. Aber wer hält dann den Haushalt am Laufen?
@kendelkay cooking and cleaning are my favorite acts of service 👩🏼🍳🫶🏼
Care-Arbeit oder auf Deutsch Fürsorgearbeit bezeichnet Tätigkeiten rund um Pflege und „Sich kümmern“. Darunter fallen Kinderbetreuung und -erziehung, Pflege von Angehörigen sowie Haushaltstätigkeiten und Reparaturarbeiten. Mittlerweile wird auch bezahlte Arbeit im Pflege- und Kinderbetreuungsbereich unter Care-Arbeit gefasst. Laut Statistik Austria sind Frauen in Österreich 3h42min täglich mit Hausarbeit beschäftigt, während Männer 1h58min dafür aufwenden. Diese Zahlen sind allerdings von 2008. Es folgt ein Blick darauf, was sich seither in der gerechten Aufteilung von Care-Arbeit getan hat.
Überraschende Ergebnisse bei Europavergleich
Das Europäische Institut für Gender Equality (EIGE) veröffentlicht ausführliche Daten, die sich um Geschlechtergerechtigkeit drehen. Jedes Jahr wird ein Index, basierend auf Daten in den Bereichen Gesundheit, Arbeit, Geld und mehr, erstellt. Diese Daten werden aus Befragungen hergenommen, zum Beispiel Eurofound und deren Erhebungen zu Lebensqualität (EQLS), und anschließend ausgewertet und zu übergeordneten Fragen zusammengefasst. Obwohl der Index jedes Jahr erscheint, werden teilweise Daten aus einem spezifischen Vorgänger-Jahr benutzt. Die unten dargestellten Visualisierungen reichen nur bis 2015, da ab diesem Jahr keine neuen Befragungen zu diesen Themen durchgeführt wurden und sich so die Zahlen auch nicht ändern.
Aus allen europäischen Ländern wurden für diesen Artikel, neben Österreich und dem EU-Durchschnitt, vier Länder ausgewählt, die eine geografische und auch eine politische Bandbreite abdecken sollen. So war die Hypothese bei Frankreich etwa, dass dort Care-Arbeit gerechter aufgeteilt sein könnte, da eine gute Kinderbetreuung schon lange etabliert ist und es für Frauen zur Normalität gehört, nach der Geburt rasch wieder in den Job zurückkehren. Auch Schweden hat den Ruf eines Landes, in dem die Gleichberechtigung schon weiter fortgeschritten ist. Deutschland wurde wegen der geografischen und kulturellen Nähe zu Österreich gewählt und Ungarn als Gegenpol in die Auswertung mit reingenommen. Wegen der konservativen ungarischen Regierung wurde angenommen, dass auch in Haushalten eine traditionellere Rollenverteilung herrschen könnte.
Überraschenderweise zeigen die Daten von EIGE ein anderes Bild als angenommen. Frauen in Frankreich kümmern sich mit 45,6% am meisten um Kinder und Ungarinnen sind mit 30,1% nur knapp über Schwedinnen (29,5%). Die Zahlen wirken allgemein sehr niedrig. Eine Erklärung könnte sein, dass nicht nur nach der täglichen Kinderbetreuung gefragt wird, sondern auch nach Betreuung von anderen Personen in der Familie. Auch die Fragestellung hat sich über die Jahre etwas verändert. Bei der Befragung 2002 wurde nur nach Kinderbetreuung und Betreuung von älteren oder behinderten Verwandten gefragt. In 2015 wurde zusätzlich nach Enkelkindern, Nachbar*innen und Freund*innen gefragt. Von 2010 bis 2012 verringern sich die Zahlen in Ungarn, Schweden und Deutschland merklich, was auf die geänderte Fragestellung zurückzuführen sein könnte.
Bei den Männern sind es auch die Franzosen (29,4%), die die meiste Care-Arbeit im Bereich Kindererziehung und Pflege verrichten. EU-Schnitt ist bei den Männern 25% und bei den Frauen 37%. Von 2010 bis 2012 verringern sich die Zahlen in Ungarn, Schweden und Deutschland merklich. Auch bei den Frauen ist hier in den meisten ausgewählten Ländern eine Veränderung nach unten zu sehen.
Deutlich mehr Frauen stehen hinter dem Herd
Ebenso wird die zweite Frage, die für Care-Arbeit relevant ist, sehr allgemein gehalten. “Machen Sie jeden Tag Haushaltstätigkeiten oder kochen Sie?” Was unter Haushalt verstanden wird, kann aus den EIGE-Daten nicht herausgelesen werden. Auch hier stammen die letzten Daten aus dem Jahr 2015.
Wer die Arbeit im Haushalt großteils erledigt, ist dafür jedoch recht eindeutig. Nicht nur in Österreich, sondern europaweit - wie die untenstehende Grafik zeigt. Wieder überrascht Ungarn. Nur 56% der Frauen in Ungarn kochen oder erledigen täglich den Haushalt. Das ist einiges unter dem EU-Durchschnitt von 78%. Bei den Männern schafft es nur Schweden über die 50% Hürde. Eine Verbesserung ist dort und in Österreich zu vermerken. Österreichs Männer steigen von 11% in 2010 zu 28% ab 2012 auf. Damit liegt Österreich knapp unter dem europäischen Durchschnitt von 32%. Es kommt auch bei diesen Zahlen zu großen Veränderungen von 2010 auf 2012. Hier könnte die Fragestellung die Ursache sein: Zuerst wurde nach Hausarbeit UND Kochen gefragt, ab 2012 nach Hausarbeit UND/ODER Kochen.
Wie verbringen Frauen und Männer ihre Zeit?
Da diese Fragestellung ungenau ist, bietet die Zeitverwendungserhebung der Statistik Austria einen genaueren Einblick in die Tätigkeiten von Österreicher*innen. Bei dieser Erhebung werden ca. 8.200 Personen ab zehn Jahren dazu angehalten, für einen Tag ein Tagebuch zu führen, in dem alle Tätigkeiten niedergeschrieben werden, die länger als 15 Minuten dauern. 2022/2023 findet die mittlerweile vierte Erhebung statt. Die Ergebnisse sollen im ersten Halbjahr 2023 vorliegen.
Öffentlich zugänglich befinden sich auf der Website von Statistik Austria nur Daten von der Erhebung 2008. Der Vorgang der Datenerhebungen 1981 und 1992 war anders und ist daher nicht gut vergleichbar. Tätigkeiten haben sich zum Beispiel im Laufe der Zeit verändert und wurden neu kategorisiert. Dennoch geben die Daten aus 2008 Einblicke in die unbezahlten Tätigkeiten der Österreicher*innen.
Im folgenden Balkendiagramm ist die Zeitverwendung für Haushaltstätigkeiten abgebildet. Es wurden nur jene ausgewählt, die auch in ausreichendem Ausmaß dokumentiert wurden (über 35% aller Teilnehmenden haben diese Tätigkeit erfasst). Die Grafik zeigt, Frauen liegen bei Haushaltstätigkeiten deutlich vorne.
Unterschiedliche Wahrnehmung der Care-Arbeitsbeteiligung zwischen Frauen und Männern
Geschlossene Schulen und Kindergärten, Homeoffice und Lockdowns - Kinderbetreuung ist vor allem in Pandemiezeiten ein großes Thema. Die wohl aktuellsten Daten stammen aus einer Studie des European Institute for Gender Equality aus dem Jahr 2021, worin Menschen im Alter von 20-64 Jahren zu Themen wie Kinderbetreuung, Haushalt und flexibles Arbeitsabkommen während der Coronapandemie befragt wurden.
Dabei sticht eines hervor: Die Wahrnehmung von Frauen und Männern differenziert sich. So finden sowohl EU-weit als auch in Österreich mehr Männer als Frauen, dass beide Geschlechter ungefähr gleichbeteiligt an der Aufsicht von Kindern gewesen seien. Außerdem geben 59% der befragen Frauen und nur 11% der befragten Männer in Österreich an, dass sie sich hauptsächlich alleine um die Kinder gekümmert haben. Damit liegt Österreich mit der Beteiligung der Männer unter dem EU-Schnitt von 23%. Haushaltsfremde Personen wurden kaum eingestellt.
Wird genauer ins Detail gegangen, so geben während der Pandemie 40% der Frauen in Österreich an, die (Enkel-)Kinder täglich mehr als 4 Stunden zu betreuen. Damit befindet sich Österreich im EU-Schnitt. Bei den Männern in Österreich sind es 20%, der EU-Schnitt 21%.
Auch oder gerade während Pandemiezeiten muss sich neben Kindern ebenso um den Haushalt gekümmert werden. Ein von der Grafik zur Kinderbetreuung bereits bekanntes Phänomen tritt auch in der Beantwortung dieser Frage auf: Österreich- und EU-weit haben mit 43% bzw. 40% deutlich mehr Männer als Frauen (23% bzw. 22%) das Gefühl einer gleichmäßigen Aufteilung. Komplett oder meistens übernehmen nach den Angaben mit 68% wesentlich mehr Frauen Haushaltsarbeiten als Männer (15%). Auch hier schneidet Österreich schlechter ab als der EU-Schnitt.
Fazit
Egal ob "Stay-at-Home Girlfriend" oder nicht, Frauen in der EU übernehmen den Großteil der Care-Arbeit. Österreichs Männer verbringen laut den Daten noch weniger Zeit mit Hausarbeiten und Kinderbetreuung als im EU-Durchschnitt. Dennoch schneiden andere EU-Länder mit der Verteilung von Care-Arbeit teils nicht wesentlich besser ab oder liefern überraschende Ergebnisse, wie etwa Frankreich oder Ungarn. Trotz konservativer Regierung wirkt letzteres im Care-Arbeits-Vergleich fortschrittlicher als Österreich.
Ist Österreich folglich rückschrittlich? Dass die "50er-Jahre Hausfrau" generell wieder im Kommen ist, davon kann nicht gesprochen werden. Eine wirkliche Verbesserung ist aber in den Daten ab 2010 auch nicht erkennbar. Abzuwarten bleibt die kommende Zeitverwendungserhebung der Statistik Austria. Drastische Veränderungen sind jedoch vermutlich nicht erwartbar. Faktoren wie der Gender-Pay-Gap, wonach Männer bei gleicher Arbeit immer noch mehr verdienen als Frauen, oder mangelndes Kinderbetreuungsangebot vor allem in ländlichen Kreisen können neben stereotypen Ansichten dazu beitragen, dass Frauen in Österreich immer noch vermehrt die Care-Arbeit übernehmen. Von Gerechtigkeit oder Gleichstellung kann bei unbezahlter Care-Arbeit in Österreich also nicht gesprochen werden. Die Denkfabrik Momentum Institut empfiehlt dahingehend etwa eine verpflichtende Väterkarenz und ein Verbot von ungleicher Bezahlung für dieselbe Arbeit.
Doch warum sollte uns die Geschlechterdiskrepanz überhaupt kümmern? Weil sie negative Auswirkungen auf Frauen hat. Wenn eine finanzielle Abhängigkeit besteht, ist es beispielsweise für Frauen, die von häuslicher Gewalt betroffen sind, schwieriger, dieser zu entkommen. Teilzeitarbeit, schlechter bezahlte Jobs, Gender-Pay-Gap, unbezahlte Care-Arbeit: das alles kumuliert für viele Frauen in der Armutsgefährdung im Alter. Um dem zu entkommen, braucht es Reformen - politische, wie auch gesellschaftliche. In diesem Sinne: Frauen, raus aus den Küchen.
Inflation in Österreich
Seit mehreren Monaten hört man immer wieder von der steigenden Inflation. Aber was ist das genau? Wie wirkt sie sich auf unseren Alltag aus und wieso gibt es sie überhaupt?
Was ist Inflation?
Unter Inflation versteht man grundsätzlich das steigende Preisniveau von Waren und Dienstleistungen. Dabei ist zwischen der Preissteigerung einzelner Produkte aufgrund von Angebot und Nachfrage zu unterscheiden: Bei der Inflation steigt der Preis allgemein, nicht nur von einzelnen Produktgruppen.
Berechnet wird die Inflation mithilfe der VPI, dem Verbraucherpreisindexes.
Inflation bedeutet also, dass man im Laufe der Zeit weniger für sein Geld bekommt. Für den einzelnen Verbraucher ist dies zwar nicht erfreulich, die Europäische Zentralbank hingegen gibt eine jährliche Inflationsrate von 2% als erstrebenswert an, da sie so niedrig, stabil und vor allem berechenbar bleibt. Schwankt die Rate von Jahr zu Jahr zu sehr, wird es zunehmend schwieriger langfristige volkswirtschaftliche Entscheidungen zu treffen. (Quelle: Europäische Zentralbank)
Um die Inflation im täglichen Leben besser zu verstehen, gibt es den Mikrowarenkorb. Darunter versteht man einen fiktiven Warenkorb, der den täglichen Einkauf simulieren soll. Darin befinden sich 20 Waren und Dienstleistungen. In den letzten Jahren sind vor allem die Preise von Nahrungsmittel, Treibstoffe und Freizeitbeschäftigungen deutlich gestiegen und übersteigen somit deutlich die offizielle Inflationsrate. Mit dem Mikrowarenkorb wird also versucht die „gefühlte Inflation“ darzustellen, also die Teuerung, die man im täglichen Leben zu spüren bekommt. (Quelle: Statistik Austria)
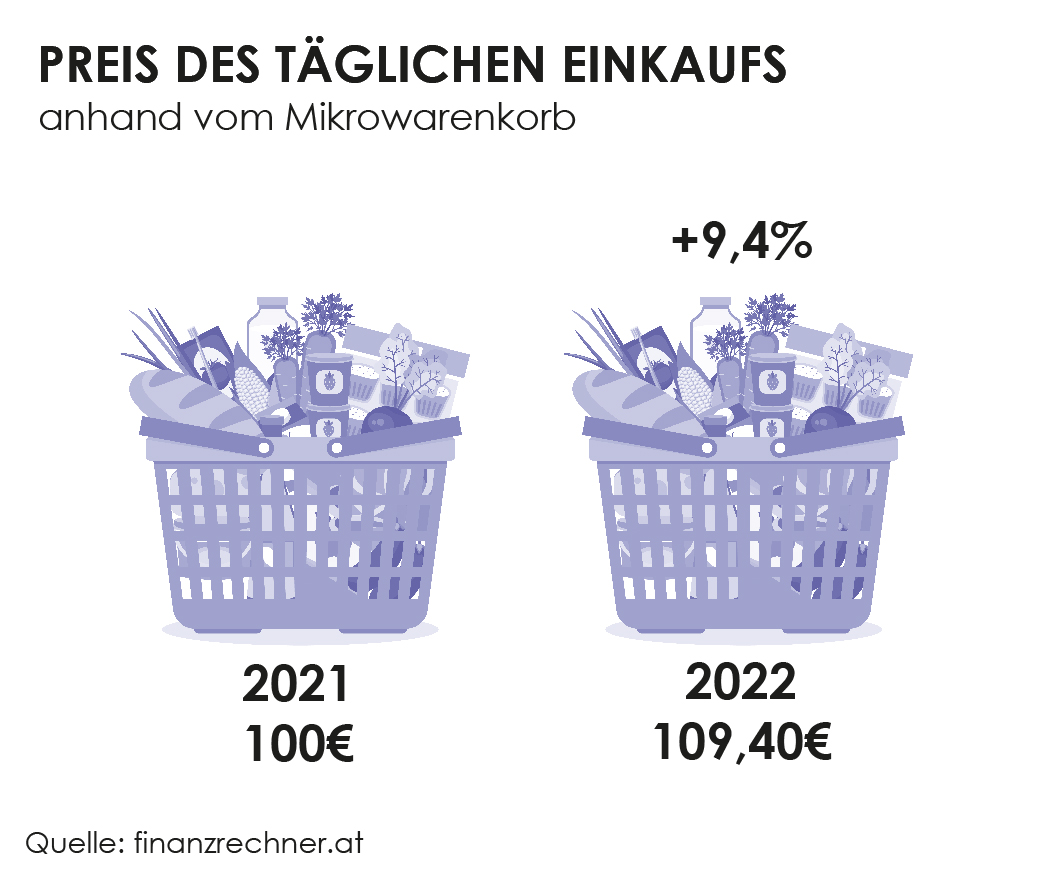
Das Preisniveau des Mikrowarenkorbs ist von 2021 auf 2022 um 9,4% gestiegen. Das heißt also wenn man vor einem Jahr noch 100€ für seinen Einkauf bezahlt hatte, kostet derselbe Einkauf ein Jahr später, also 2022, schon 109,40€. (Quelle: finanzrechner.at)
Wie hat sich die Inflation in den letzten Jahren in Österreich entwickelt?
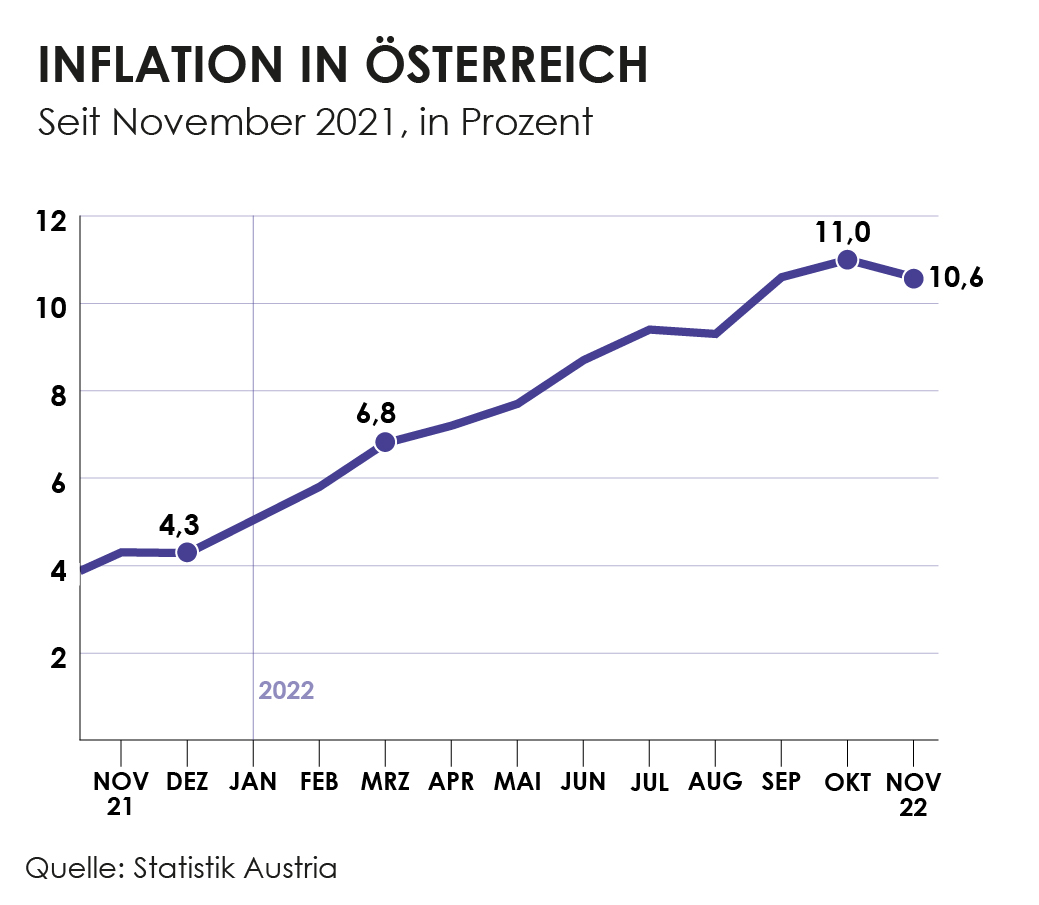
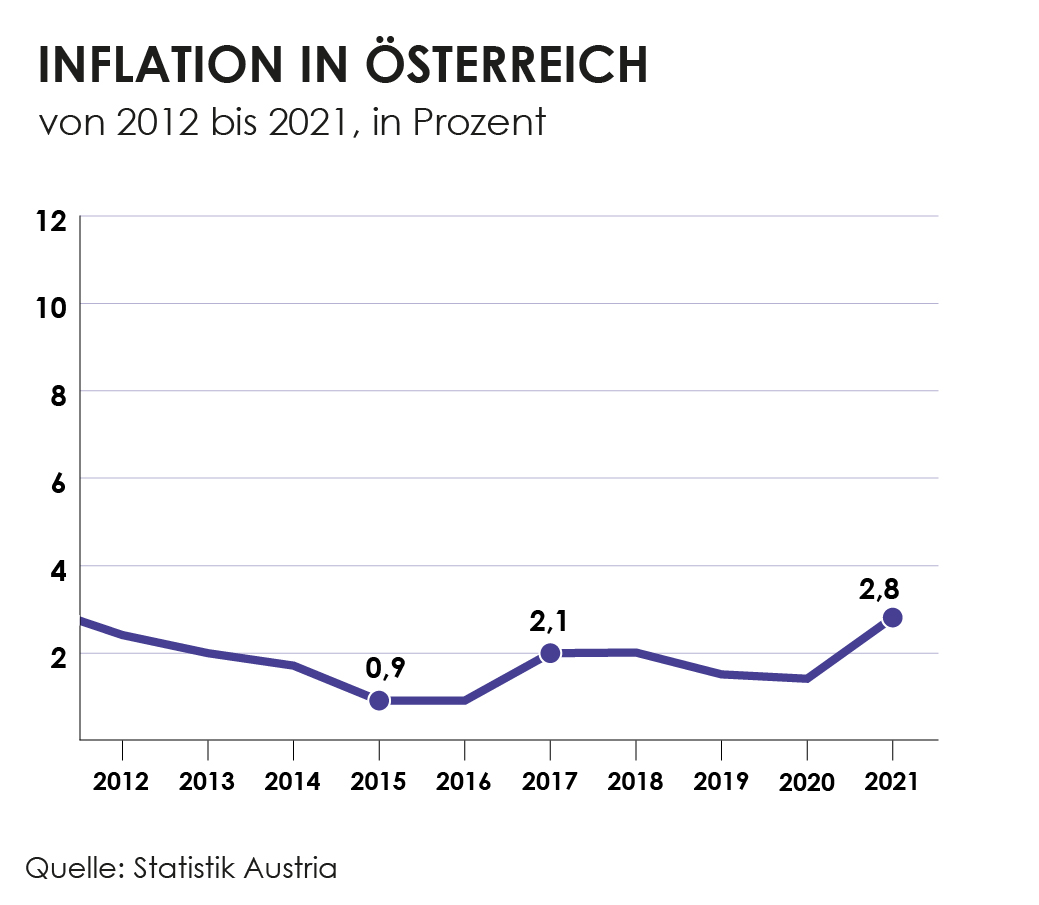 Sieht man sich die Inflation in Österreich in den letzten 10 Jahren an sieht man, dass das Ziel von 2% kaum überstiegen wurde, beziehungsweise oft sogar nur bei rund 1% lag. 2022 hingegen stieg sie sehr stark an, mit Rekordwerten in den Herbstmonaten. Was sind die Gründe dafür? Zum einen liegt es daran, dass die Wirtschaft zurzeit sehr schnell wieder hochfährt. Während der Pandemie konnten viele Waren und Dienstleistungen nicht in Anspruch genommen werden und Geld wurde gespart. Jetzt beginnen die Menschen wieder zu reisen oder Restaurants zu besuchen. Durch dieses Wirtschaftswachstum können Unternehmen einfacher ihre Preise erhöhen. Andere Unternehmen hingegen kommen mit der Produktion nicht mehr hinterher und erhöhen aufgrund von Angebot und Nachfrage ihre Preise.
Sieht man sich die Inflation in Österreich in den letzten 10 Jahren an sieht man, dass das Ziel von 2% kaum überstiegen wurde, beziehungsweise oft sogar nur bei rund 1% lag. 2022 hingegen stieg sie sehr stark an, mit Rekordwerten in den Herbstmonaten. Was sind die Gründe dafür? Zum einen liegt es daran, dass die Wirtschaft zurzeit sehr schnell wieder hochfährt. Während der Pandemie konnten viele Waren und Dienstleistungen nicht in Anspruch genommen werden und Geld wurde gespart. Jetzt beginnen die Menschen wieder zu reisen oder Restaurants zu besuchen. Durch dieses Wirtschaftswachstum können Unternehmen einfacher ihre Preise erhöhen. Andere Unternehmen hingegen kommen mit der Produktion nicht mehr hinterher und erhöhen aufgrund von Angebot und Nachfrage ihre Preise.
Zum anderen ist die Inflationsrate so hoch, da sie letztes Jahr niedrig war. Man vergleicht zur Berechnung immer die Preise des Vorjahresmonats, sind diese nun niedrig ist die Differenz zum nächsten Jahr höher als erwünscht. Dieses Phänomen nennt man Basiseffekt. (Quelle: Europäische Zentralbank)
Wie sieht es in anderen Ländern aus?
Vergleicht man die Inflationsraten innerhalb Europas zieht man hierzu den HVPI, also den harmonisierten Verbraucherpreisindex, als Grundlage heran. Im Gegensatz zum VPI wird er mit einheitlichen Definitionen berechnet, das heißt die Inflationsraten der einzelnen Europäischen Länder sind vergleichbar, da sie nach dem gleichen Schema berechnet werden. (Quelle: Eurostat)
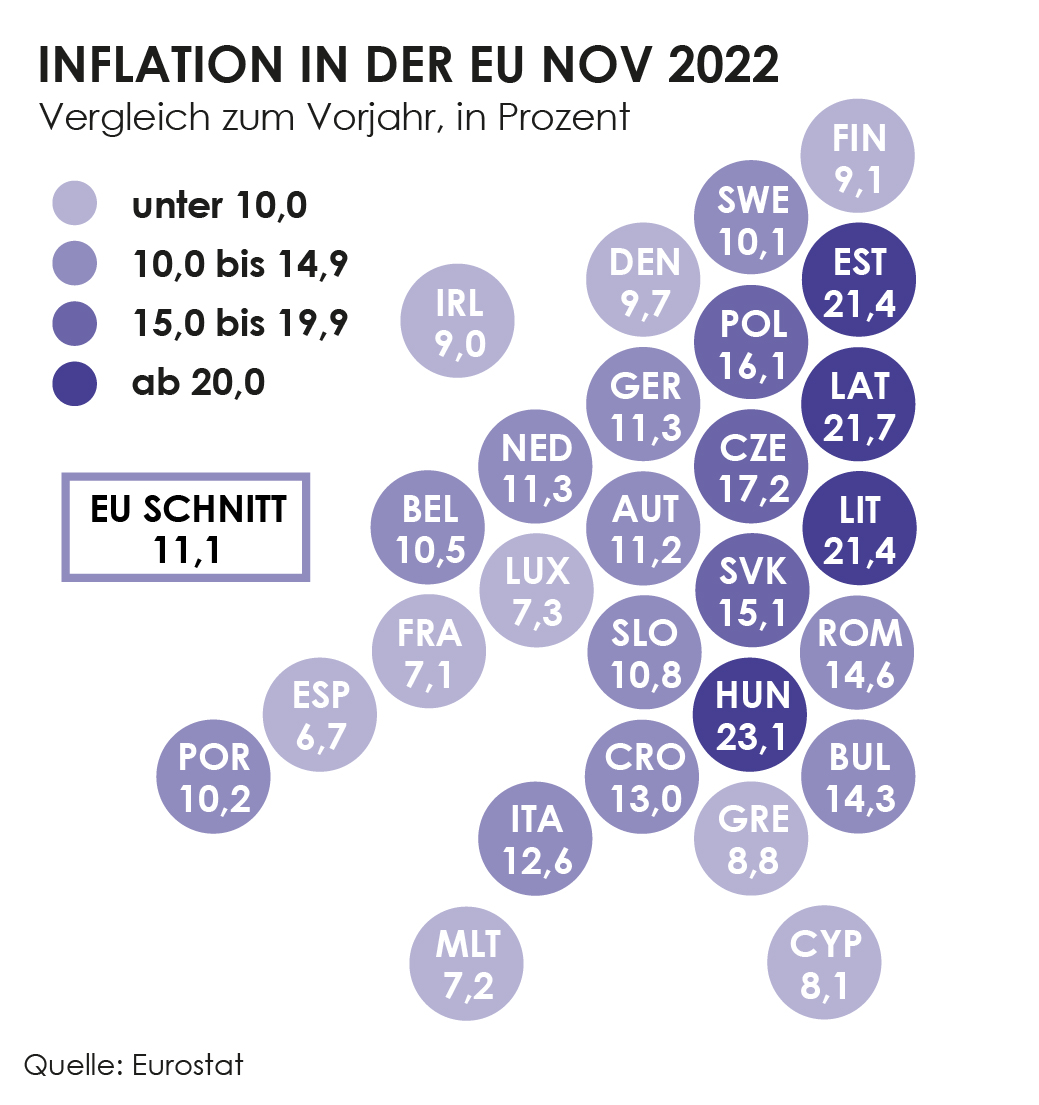
Im Ländervergleich der EU sieht man, dass sich die meisten Länder unter dem EU-Durchschnitt von 12,6 Prozent befinden. Auch Österreich liegt mit 11,2 Prozent auch knapp unter diesem Wert. Am höchsten ist die Inflation in den baltischen Ländern, welche auch stärker von den Folgen des Ukraine Kriegs betroffen sind als das westliche Europa.
Auch in Ungarn ist die Inflationsrate mit 23,1 Prozent auffällig hoch. Damit fällt es zusammen mit Estland, Lettland und Litauen zu den einzigen EU-Ländern, in denen die Inflation über 20 Prozent beträgt.
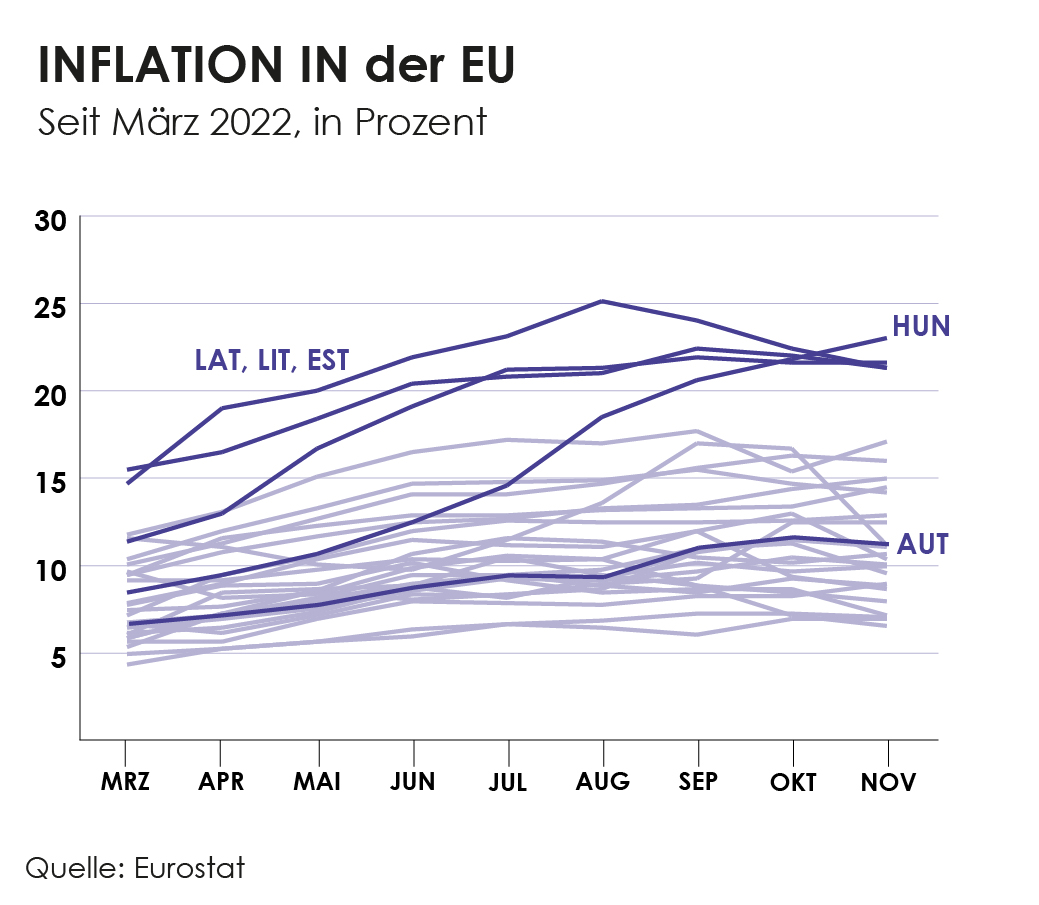
Die Entwicklung der Inflation seit März zeigt, dass die baltischen Staaten, also Estland, Lettland und Litauen schon im Frühling eine viel höhere Inflationsrate aufgewiesen haben als die restlichen EU-Länder. Interessant ist auch die Entwicklung von Ungarn. Dort war die Inflationsrate bis in den Sommer relativ im EU-Schnitt, erst im August stieg sie auf 18 Prozent an und überholte im November schließlich alle anderen EU-Länder mit einer Inflationsrate von 23 Prozent.
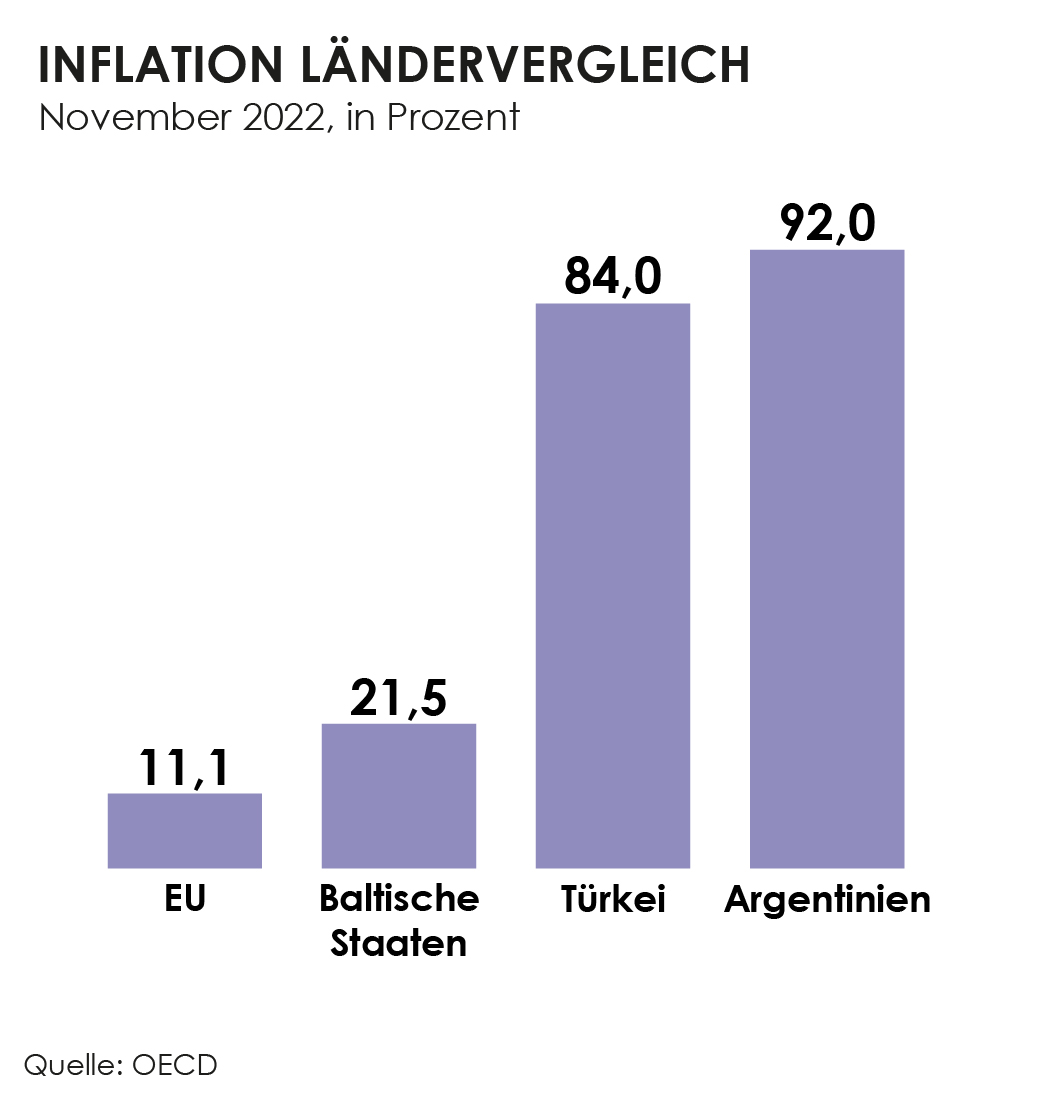
Sieht man sich die Länder außerhalb der EU an, fällt vor allem die Türkei mit 84% Inflationsrate und Argentinien mit 92% auf. Das heißt also dass in Argentinien bestimmte Produkte und Dienstleistungen fast doppelt so viel kosten als im Jahr 2021. Wenn sich die Inflationsrate in kurzer Zeit so stark erhöht spricht man von einer Hyperinflation. Solche haben wir auch schon in Österreich vor 100 Jahren erlebt, wo plötzlich ein Laib Brot 1 Billionen Reichsmark kostete.
Ausblick
Wie geht es nun weiter in Österreich? Die Statistik Austria geht davon aus, dass die Inflationsrate auch 2023 nicht wieder so schnell normalisiert. Man geht von einer Teuerung um 6,5 Prozent im Vergleich zum Vorjahr, also 2022 aus. Die Preise steigen also weiter. Erst 2024 geht man von einer niedrigeren Inflationsrate von 3,2 Prozent aus. Bis dahin heißt es für die Österreicher:innen weiterhin sparen.
Weihnachten trifft Energiekrise: Der Wiener Sparplan
Wie jedes Jahr, erstrahlt Wien auch in diesem Winter im Glanz der Weihnachtslichter. Vor allem die Innere Stadt beeindruckt mit Massen an Weihnachtsbeleuchtung, die die Straßen schmücken und das trotz Energiekrise. Ausbleibende Gaslieferungen, explodierende Strompreise und immer häufiger werdende Stromausfälle – das sind die Schlagzeilen, die alle Haushalte zum Energiesparen aufrufen. Eine denkbar schlechte Ausgangslage für die energiefressende Weihnachtszeit.
Dennoch sind sich die Wiener Kaufleute einig. Die stimmungsvollen Lichter sollen auch diesmal die Einkaufsstraßen zieren, um in diesem schwierigen Winter Zuversicht und Sicherheit zu vermitteln. Aber nicht nur die Beleuchtung braucht zusätzliche Energie. Neben dem weihnachtlichen Lichtermeer soll es nach den Entbehrungen der Pandemiejahre auch wieder ´Christkindlmärkte und Eislaufplätze geben. Es stellt sich also die Frage: Ist das noch vertretbar? Ist die Adventszeit tatsächlich der Energiefresser schlechthin und wie wirkt sich das auf die Energielage in Wien aus?
Um diese Fragen zu beantworten, gilt es zuerst allerding einen genaueren Blick auf Österreichs Energielage und die Versorgungssicherheit werfen.
Energieverbrauch pro Haushalt
Sucht man das Wort „Energiekrise“ online wird man augenblicklich mit dutzenden Fachbegriffen und abstrakte Maßeinheiten konfrontiert. Eine Tatsache die das Thema für viele Endverbraucher:innen mehr als undurchsichtig macht. Dabei ist es wichtig, zu wissen, dass der Verbrauch von Strom und Gas üblicherweise in Kilowattstunden gemessen wird. Im Großraum Wien kostet eine solche Kilowattstunde durchschnittlich 25 Cent. So viel kostet es zum Beispiel das Mittagessen für vier Personen auf einem Elektroherd zu kochen, oder 15 Hemden zu bügeln.
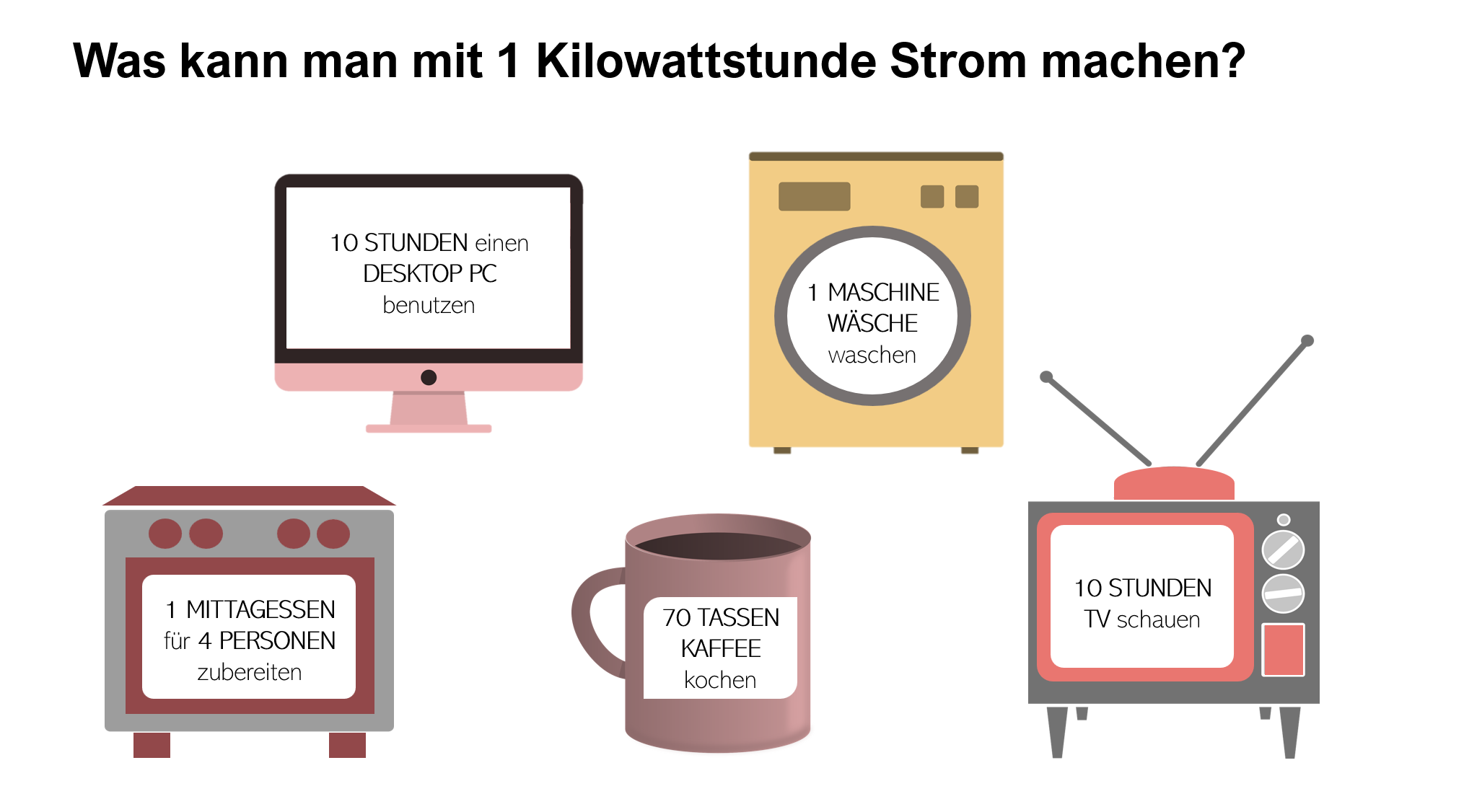
Quelle: Verivox GmbH, Eigene Darstellung
Laut Bundesministerium für Finanzen (2023) kommt ein Zwei-Personen-Haushalt dabei auf einen durchschnittlichen Stromverbrauch von rund 3.000 Kilowattstunden pro Jahr. Für eine durchschnittliche Wiener Hauptwohnsitzwohnung von 75 m² kommen noch einmal rund 10.500 Kilowattstunden für den jährlichen Gasverbrauch hinzu. Das ergibt überschlagsmäßig einen täglichen Durchschnittsverbrauch von 37 Kilowattstunden pro Tag und Haushalt. Der Großteil dieses Energiebedarfs entsteht vor allem durch das Heizen, während die Produktion von Warmwasser und Küchengeräte nur einen Bruchteil dieser Energie benötigen.
Die österreichische Bevölkerung spart
Die Angst vor dem diesjährigen Winter und einer damit einhergehenden Versorgungsknappheit war jedenfalls groß. Betrachtet man allerdings rückblickend die Ausgangslage im vergangenen Herbst, geben die Zahlen nur wenig Grund dazu.
Bereits im November 2022 ist der monatliche Gasverbrauch im Vergleich zum Vorjahresmonat um 20,1 Prozent gesunken. Gleiches gilt für den Stromverbrauch, der sich um 6,7 Prozent reduziert hat. Der Trend zeigt also klar: die österreichische Bevölkerung spart. Allerdings weist das Österreichische Institut für Wirtschaftsforschung darauf hin, dass ein großter Teil dieser Einsparung der milden Temperaturen geschuldet ist. Unter Berücksichtigung des Wetters lag die Einsparungsleistung zwischen Oktober und November nur bei sieben Prozent. Ob nun Glück mit dem Wetter oder fleißige Sparanstrengungen, auch der Blick auf die Gasspeicherstände zu Beginn des Winters geben vorerst Entwarnung – zumindest in Hinblick auf die Versorgungssicherheit für die Wintersaison 2022/23. Laut Daten der AGSI (eine Datenplattform, die Gasfüllstände der EU ausweist und vergleicht) waren die österreichischen Gasspeicher zum Stichtag 1. November 2022 zu rund 93 Prozent gefüllt (86.5469 TWh). Ein Höchststand, wenn man diese Zahl mit den Füllständen von den vergangenen Jahren zu Beginn des Winters vergleicht.
Eine Ausgangslage die im ersten Moment wenig alarmierend scheint. Dennoch bleibt zu berücksichtigen, dass Österreichs Versorgungsstrategie, die zu ungefähr 80 Prozent auf Gaslieferungen aus Russland gebaut hat, durch die andauernden Konflikte Russlands mit der Ukraine, nachhaltig erschüttert. Zwar hat sich die OMV bereits Transportkapazitäten für Gas aus Norwegen gesichert. Dennoch ist die Gaskrise für Europa noch nicht überstanden. Dementsprechend bleiben viele Fragen rund um die langfristige Versorgungssicherheit offen, weshalb die Diskussion um den zusätzlichen Energieverbrauch und die damit verbundenen Energiekosten rund um die Weihnachtszeit immer wieder neu angeheizt wird. Aber ist diese ganze Aufregung gerechtfertigt oder handelt es sich dabei nur um heiße Luft?
Die Zeit der vielen Lichter
Stimmungsvolle Lichter, soweit das Auge reicht. Damit assoziieren wohl die meisten die Zeit rund um Weihnachten. Dementsprechend waren sich die Wiener Vertreter:innen trotz Energiekrise schnell einig: Verzichten möchte man auf nichts – reduzieren wäre ein Kompromiss. Unter dieser Prämisse wurden die Wiener Einkaufsstraßen in diesem Winter erstmals am 18. November 2022 erhellt. Eine Woche später als üblich. Von da an konnten Passanten und Passantinnen die typische Wiener Weihnachtsbeleuchtung täglich ab 15 Uhr bewundern. Bis um 22 Uhr die Lichter ausgeknipst wurden. Ebenfalls 2 Stunden früher als noch im Vorjahr.
Mit diesen Maßnahmen wurde die Leuchtzeit bereits von den bisherigen 660 Stunden auf 364 Stunden reduziert. Zusätzlich konnte die Stadt Wien mit der vollständigen Umstellung auf LED-Lampen rund 45 Prozent an Energie einsparen. Dennoch wurde der benötigte Strombedarf für die Weihnachtsbeleuchtung, vor Beginn der Adventszeit, auf 49.000 Kilowattstunden geschätzt. Das entspricht dem Jahresstromverbrauch von insgesamt 14 Haushalten.
Nicht nur die Stadt Wien, sondern auch private Haushalte wollen den weihnachtlichen Energieverbrauch einbremsen. Das zeigt zumindest eine Umfrage der Tageszeitung Kurier im Dezember 2022. Demnach wollten rund 76 Prozent der Befragten durch eine Reduktion der Weihnachtsbeleuchtung Strom sparen. Dafür empfehlen Energieverbände, neben der Verwendung von Zeitschaltuhren, vor allem eines: die Umstellung auf LED-Lampen. Diese benötigen im Schnitt nämlich 80 Prozent weniger Energie und können somit deutlich zum Sparen beitragen. Immerhin verbraucht eine herkömmliche Lichterkette täglich mehr Strom als ein moderner Kühlschrank.
20 Prozent weniger Gesamtenergiebedarf an den Feiertagen in Wien
In Wiener Haushalten wird während den Weihnachtsfeiertagen gekocht, gebacken und gebraten, was das Zeug hält. Dementsprechend liegt der durchschnittliche Mehrverbrauch an Strom an den Feiertagen bei rund 10 Kilowattstunden pro Tag. Es wird also rund doppelt so viel Strom als normal gebraucht. Trotzdem geht der Gesamtenergiebedarf, laut Daten der Wiener Netze, im Vergleich zu normalen Werktagen, während dieser Tage im Großraum Wien um rund 20 Prozent zurück. Ein Phänomen, dass vor allem dadurch zum Vorschein kommt, dass viele Wiener:innen zu ihren Familien in andere Bundesländer fahren und Büros, Industrie und Geschäfte geschlossen haben. Es ist also nicht als ein tatsächlicher Rückgang, sondern eher als eine Art räumliche Umverteilung des Energiebedarfs zu sehen.
Christkindlmärkte und Wiener Eistraum in der Kritik
In der Bundeshauptstadt machen die Wiener Christkindlmärkte die weihnachtliche Atmosphäre komplett. 2022 gab es nach zwei mauen Pandemiejahren insgesamt 17 Märkte mit über 900 Ständen. Ein neuer Rekord in Wien. Diese vielen Lichter bleiben selbstverständlich nicht unbemerkt und summieren sich pro Weihnachtsmarkt auf einen durchschnittlichen Verbrauch von rund 70.000 Kilowattstunden, was ungefähr einem Jahresstromverbrauch von insgesamt 20 Haushalten entspricht.
Hinzukommen noch Heizstrahler, die im Vergleich dazu die größeren Energiefresser darstellen. Innerhalb einer Stunde verbrauchen diese nämlich ungefähr so viel Energie wie eine Waschmaschine in 3 bis 4 Durchgängen. Aufgrund dessen, haben die meisten großen Weihnachtsmärkte dieses Jahr auf deren Einsatz verzichtet.
Während nach Weihnachten all die Punschhütten wieder verschwinden und die Beleuchtung abgehängt wird, ist die Energiediskussion in Wien noch nicht zu Ende. Denn am 19. Jänner eröffnet standesgemäß der Wiener Eistraum. Die größte Open-Air-Kunsteisbahn der Welt. Ein Titel, den sich die Stadt offenbar nicht nehmen lassen wollte. Denn während andere Städte wie Dornbirn oder Stuttgart und Karlsruhe in Deutschland ihre Eislaufplätze kurzerhand in Rollschuhbahnen umwandeln, bleibt Wien bei ihrem Konzept, allerdings auch hier mit Einsparungen. Mit einer 1000 m² kleineren Eisfläche und einer optimierten Kühltechnik, soll laut Prognosen der Stadt Wien rund 20 Prozent an Energie eingespart werden. Eine Reduktion, die am Ende einen geschätzten Verbrauch von rund 800.000 Kilowattstunden hervorbringt. Das kommt dem Jahresenergieverbrauch von rund 190 Haushalten gleich.
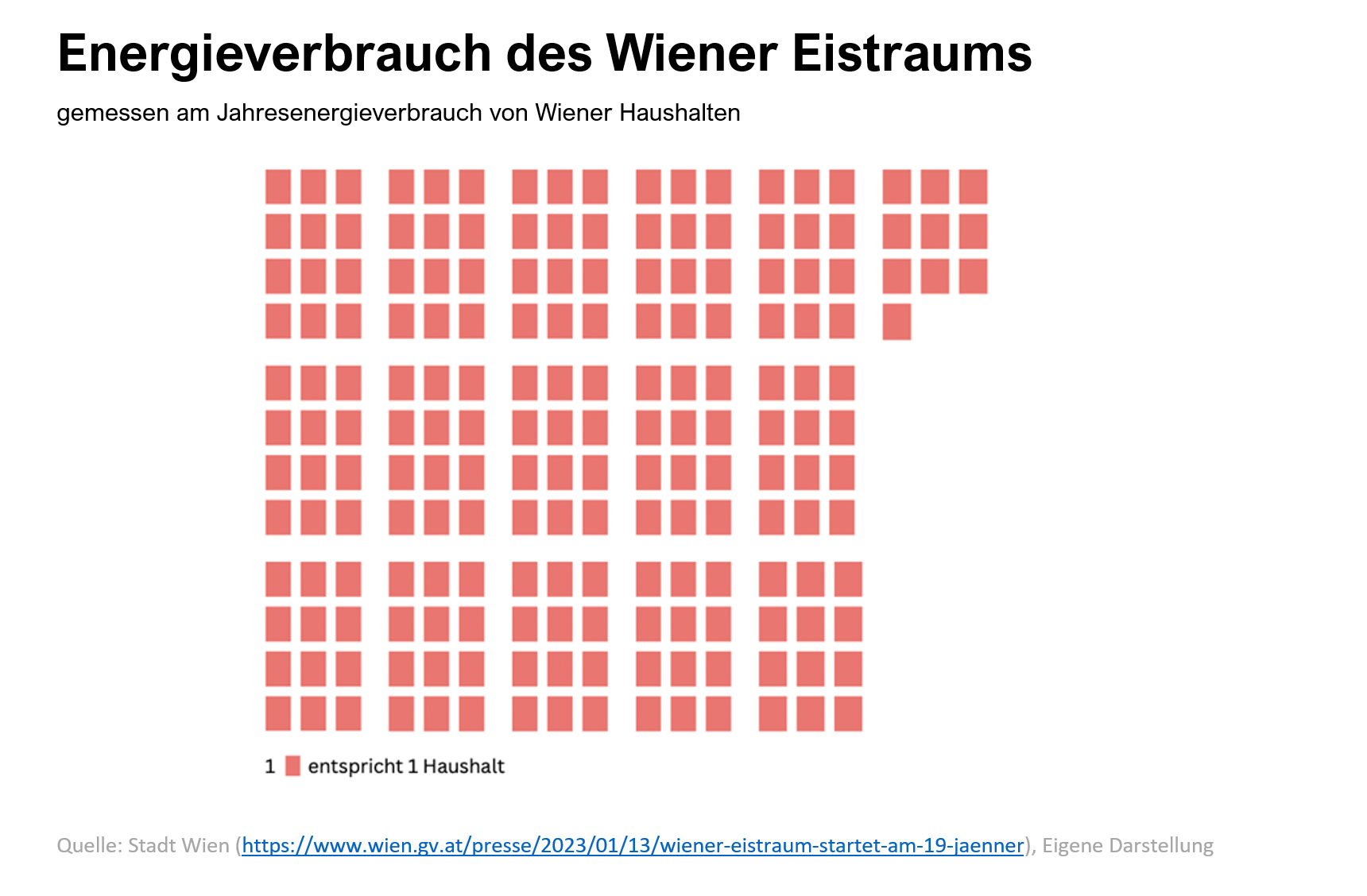
Quelle: Stadt Wien, Eigene Darstellung
Fazit
Es ist also nicht von der Hand zu weisen, dass die Weihnachtszeit durchaus einen höheren und zusätzlichen Energiebedarf fordert. Die größten Posten, also die öffentliche Beleuchtung, die Weihnachtsmärkte, sowie der Wiener Eistraum verursachen einen zusätzlichen Jahresstromverbrauch von 354 Haushalten und einen zusätzlichen Jahresgesamtenergiebedarf von insgesamt 190 Haushalten. Das klingt erstmal viel und das ist es auch. Setzt man diese Zahl allerdings in Relation zu den knapp 930.000 Haushalten in Wien, scheint dieser Mehrbedarf nicht allzu sehr ins Gewicht zu fallen.
Zumal weniger als ein Drittel des Energieverbrauchs auf private Haushalte entfällt. Was in Wien speziell hinzukommt, ist, dass Strom und Wärme im Winter häufig komplementär produziert werden. So wird die Abwärme aus den Kraftwerken zur Stromerzeugung für die Fernwärme genutzt. Damit tatsächlich weniger Energie verbraucht würde, müsste also sowohl beim Heizen wie auch beim Stromverbrauch gleichzeitig eingespart werden.
Selbstverständlich ist Energiesparen wichtig, sowie sich Gedanken, um die Umwelt zu machen ist wünschenswert und nötig. Dennoch sollte das eigentlich das gesamte Jahr über relevant sein und nicht nur während der Weihnachtszeit. Das bestätigt Sabine Seid von der Umweltberatung Wien. In einem Interview mit dem ORF sagte sie: „Weihnachten ist nur ein Tag im Jahr, ganz wichtig ist es aber, auch in den restlichen 364 Tagen möglichst umweltfreundlich und energiesparend zu leben.“

Verteilungsfrage
Mehr als 100.000 Menschen haben 2022 in Österreich um Asyl angesucht, damit wurde erstmals die Marke von knapp 90.000 Asylanträgen im Jahr 2015 überstiegen. 2015 und 2016 sind mehr als 2 Mio. Menschen nach Europa geflüchtet, damals sprach man vor allem in der Politik von einer „Flüchtlingskrise“ und auch jetzt, wo die Zahl der gestellten Asylanträge wieder steigt, wird die Asylfrage zum Politikum, die FPÖ spricht etwa von einem Asylchaos. Doch ist das vergangene Jahr 2022 mit der Fluchtbewegung 2015/16 vergleichbar und welche Rolle spielt der Krieg in der Ukraine?
Quelle: BMI
Nicht in der Zahl der Asylanträge berücksichtig sind ukrainische Vertriebene. Seit Beginn des russischen Angriffskriegs gegen die Ukraine sind laut dem UNO-Flüchtlingskommissariat knapp 8 Mio. Menschen aus der Ukraine geflüchtet, rund 5 Mio. haben in der EU und in der Republik Moldau vorübergehenden Schutz beantragt. Nach einem Beschluss des europäischen Rats, vom 4.3.2022, fallen ukrainische Geflüchtete in die Massenzustrom Richtlinie, sie müssen demnach keinen Asylantrag stellen und erhalten im Ankunftsland vorübergehend subsidiären Schutz. In Österreich haben im vergangenem Jahr 90.994 ukrainische Flüchtlinge subsidiären Schutz erhalten und haben damit auch Anspruch auf Grundversorgung.
Quelle: BMI
Die Grundversorgung ist eine Basisversorgung durch den Staat, sie ist niedriger als Sozialhilfe oder Mindestsicherung. Auch Ukrainer:innen, die ihren Lebensunterhalt nicht selber decken können, steht die Grundversorgung zu. Anfang Dezember 2022 waren 92.561 Menschen in Grundversorgung.
Von den rund 93.000 Personen, die Anfang Dezember Grundversorgung erhalten haben, entfällt ein Großteil auf Vertriebene Ukrainer:innen, die in Österreich subsidären Schutz erhalten. Rund 37.026 Personen sind Schutzsuchende und Asylwerber:innen aus anderen Ländern. Ein Großteil der Asylwerbenden, die einen Asylantrag gestellt haben, wurde lediglich bei der Durchreise registriert oder verließ Österreich wieder und bezieht keine Grundversorgung, sie erscheinen deshalb auch nicht in der Statistik, da sie Österreich wieder verlassen haben. Ein Fünftel aller Asylwerbenden erhielten im vergangenem Jahr einen Aufenthaltstitel. Demnach tauchen Asylwerbende, die beispielsweise über Ungarn nach Österreich kommen in der Asylstatistik auf, da sie bei der Einreise registriert werden, nutzten Österreich aber lediglich zur Durchreise, sie nehmen also keine Grundversorgung durch Österreich in Anspruch.
Quelle: Land Kärnten
Ein Vergleich mit 2015/16 ist daher hinfällig, da die Zahl der Asylwerber:innen, die in Österreich bleiben und Unterstützungsleistungen beziehen weitaus niedriger ist. Nichtsdestotrotz wurde die Versorgung der Personen zum Politikum. Die Diskussion, um die Unterbringung der Schutzsuchenden wird in den vergangenen Wochen heftig diskutiert, so sollen etwa im steirischen Kindberg ab Anfang Februar 250 Asylwerbende untergebracht werden, was in der Gemeinde für viel Widerstand gesorgt hat. Damit Geflüchtete proportional auf alle neuen Bundesländer verteilt untergebracht werden, gibt es eine Asylquote, die nur von Wien eingehalten wird. Wien betreut weitaus mehr Menschen mit Grundversorgung als durch die Quote vorgesehen ist. Alle anderen acht Bundesländer stellen nicht genügend Quartiere zur Verfügung. Die Bundesländer kommen hier ihrer Verantwortung nicht nach, die Debatte um die Verteilungsqoute innerhalb der EU wird mit Hinsicht auf das Verteilungsproblem in Österreichs zur weit entfernten Utopie, vor allem dann, wenn sich Länder wie Ungarn schon jetzt nicht an bestehendes EU-Recht halten und Flüchtlinge nach Österreich durchwinken.
Wie barrierefrei ist Wien?
Am Heimweg noch kurz etwas aus dem Geschäft holen oder sich auf einen schnellen Café in ein Lokal setzen. Für den Großteil von uns ist das eine Selbstverständlichkeit. Für die über 1 Millionen Menschen in Österreich, die mit einer Behinderung leben, können diese Alltäglichkeiten aber eine umfassende Vorausplanung voraussetzen oder unter Umständen aufgrund von Barrieren überhaupt nicht möglich sein.
Seit 01. Januar 2016 müssen gemäß Bundes-Behindertengleichstellungsgesetz alle Geschäfte und Gastronomiebetriebe in Österreich barrierefrei zugänglich sein. So zumindest die Theorie. Das Gesetz soll die Ungleichbehandlung von Menschen mit Behinderungen im öffentlichen Leben verhindern. In Wien alleine gibt es laut Wirtschaftskammer beispielsweise über 6000 Restaurants und Kaffeehäuser. Sie alle wären per Gesetz verpflichtet, ihre Räumlichkeiten barrierefrei zugänglich zu machen. Doch wie barrierefrei sind Gastronomie und Einzelhandel in Wien tatsächlich?
1.Menschen mit Behinderungen in Österreich
1,34 Millionen Menschen in Österreich, also 18,4% der Bevölkerung, leben mit einer dauerhaften Beeinträchtigung. Das geht aus den Mikrozensus-Zusatzfragen der Statistik Austria aus dem 4.Quartal 2015 hervor. Der Mikrozensus erhebt diese Daten nicht jährlich, die Ergebnisse aus 2015 sind daher die aktuellsten Informationen zur Anzahl von Menschen mit Beeinträchtigungen in Österreich. Die Datenlage zu Menschen mit Beeinträchtigungen ist in Österreich generell nicht sehr umfangreich.
Vor den vorliegenden Daten aus 2015 fand die letzte Erhebung der Daten im Zuge der Mikrozensus-Zusatzfragen im Jahr 2007 statt. So kann beispielsweise derzeit keine Aussage getroffen werden, wie und ob sich die Covid-19 Pandemie auf die Daten ausgewirkt hat.
Die am häufigsten angegebene dauerhafte Beeinträchtigung sind Probleme bei der Beweglichkeit. An zweiter Stelle folgen psychische Beeinträchtigungen, gefolgt von Seh- und Hörbehinderungen und geistigen Problemen beziehungsweise Lernschwächen. Interessant ist, dass Frauen sowohl von Beeinträchtigungen bei der Beweglichkeit als auch von psychischen Problemen stärker betroffen sind als Männer.
Es verwundert nicht, dass die Datenlage zur Barrierefreiheit in Österreich ähnlich schlecht gestellt ist. Möchte man erfahren, wie barrierefrei die Wiener Innenstadt, ihre Gastronomie und ihr Einzelhandel ist, stellt man fest, dass es keine zentrale Stelle gibt, die diese Daten erhebt. Das dürfte auch den Interessenvertretungen aufgefallen sein, der ÖZIV Bundesverband für Menschen mit Behinderungen erhebt daher seit 2016 die Barrierefreiheit in den Wiener Einkaufsstraßen.
2.Barriefreiheit in Wien, gemessen an den Einkaufsstraßen
2014, 2016, 2018 und 2020 wurden Erhebungen zur Barrierefreiheit der Wiener Einkaufsstraßen vom ÖZIV durchgeführt, bei der die Anzahl der Stufen vor den Geschäftslokalen im Mittelpunkt standen. Da wie erwähnt laut dem Bundesgesetz über die Gleichstellung von Menschen mit Behinderungen (BGStG) Diskriminierungen durch Barrieren seit 2016 verboten sind, sollten Geschäftslokale einen stufenlosen Eingang haben.
Leider hat sich die Barrierefreiheit seit in Kraft treten des Gesetzes nicht wirklich gebessert. 2014 waren 41,3% Geschäftslokale der untersuchten Einkaufsstraßen stufenlos zugänglich. Im Jahr 2016 zeigte sich mit 44,5% eine Verbesserung, die jedoch nicht anhielt, denn 2020 waren wiederum nur 41,7% der Geschäftslokale stufenlos. Während die Anzahl der Lokale mit einer Stufe mit 41,7% im Jahr 2020 leicht gesunken ist, ist jene mit zwei, drei oder mehr als drei Stufen am Eingang seit 2014 sogar leicht gestiegen.
Im Zuge der Studie im Jahr 2020 wurden 2326 Geschäfte in 13 Einkaufsstraßen untersucht. In diesem Jahr kamen drei Einkaufsstraßen hinzu, die bis dato nicht Teil der Untersuchung waren. Die Ergebnisse zeigen, dass vor allem die kleineren Einkaufsstraßen, bei der Barrierefreiheit schlecht abschneiden. Während auf den großen, bekannten Straßen wie Mariahilfer Straße oder Kärntnerstraße deutlich über die Hälfte der Geschäfte über einen stufenlosen Eingang verfügen, sind es auf der Thalia Straße oder der Josefstädterstraße weniger als ein Viertel. Speziell die Josefstädterstraße stagniert in Sachen Barrierefreiheit seit der Ersterhebung 2016 beinahe komplett. Damals waren 23% der Geschäfte ohne Stufe, 2020 waren es 24,2%. Die Geschäfte in der Thaliastraße wurden 2020 erstmalig untersucht, die zeitliche Entwicklung kann hier also nicht beurteilt werden. Dennoch schneidet die Thaliastraße bei der Erhebung 2020 am schlechtesten von allen Straßen ab, mit nur 24% stufenlosen Eingängen.
Die Wiener Einkaufsstraße mit der höchsten Barrierefreiheit ist laut der Erhebung die Mariahilfer Straße, in der im Jahr 2020 67,5% der Geschäftslokale stufenlos zugänglich waren. Während es 2014 nur 64% waren, konnte man 2018 schon 71,5% ohne Stufe betreten. Der Abstieg auf 67,5% im Jahr 2020 könnte auf Umbauarbeiten in der Einkaufsstraße zurückzuführen sein, da einige Gebäude dadurch nicht erfasst werden konnten. Fast ein Drittel der Geschäftslokale hatten 2020 vor dem Eingang eine Stufe, 2,4% zwei Stufen und nur 0,7% aller erfassten Gebäude waren nur über 3 oder mehr Stufen zugänglich.
Es wird deutlich, dass der Großteil der Lokale in der Mariahilfer Straße mit Stufen nur eine Stufe aufweist. Bei einer Stufe sollte es also nicht allzu schwer sein durch den Einbau einer Rampe Menschen mit Behinderungen einen stufenlosen Eingang zu gewähren. Doch so einfach ist es leider nicht. Verschiedene bauliche Vorschriften in Österreich erschweren Gastronom:innen und Unternehmer:innen den Umbau oder widersprechen dem Behindertengleichstellungsgesetz sogar teilweise. So kann beispielsweise eine Rampe vor einem Geschäft nur dann gebaut werden, wenn anschließend der Gehsteig trotz Rampe noch mindestens 2 Meter breit ist. Oder, wenn ein Lokal lediglich im Bezug auf Barrierefreiheit umgebaut werden soll, muss der gesamte Betrieb auf die aktuellen technischen Standards gebracht werden, was häufig mit höheren Kosten verbunden ist.
Ebenso heißt ein stufenloser Zugang zu Geschäftslokalen nicht gleich, dass diese vollkommen barrierefrei sind, wodurch die Einkaufsstraßen-Studie des ÖZIV im Jahr 2020 um eine Online-Umfrage erweitert wurde. Somit sollen alle Menschen mit Behinderungen, auch solche mit chronischen und psychischen Erkrankungen, und ihre Einschätzung zur Barrierefreiheit der Wiener Einkaufsstraßen erfasst werden.
Wenn man nun die Erhebung der Einkaufsstraßen mit der Online-Umfrage vergleicht, merkt man, dass die Ergebnisse einigermaßen übereinstimmen. So wurden die Studienteilnehmer unter anderem gefragt, ob die Mariahilfer Straße für sie barrierefrei ist. Zwar stimmten nur 22% der Befragten der Frage vollständig zu, fast die Hälfte der Studienteilnehmer*innen stimmte aber zumindest teilweise zu. Über zwei Drittel sind also der Meinung, dass die Mariahilfer Straße für sie eher barrierefrei ist. Somit denken nur etwa 20% der Teilnehmenden, dass diese Einkaufsstraße für sie kaum oder gar nicht barrierefrei ist. Ein Anteil von über 10% kann die Barrierefreiheit der Geschäftslokale auf der Mariahilfer Straße gar nicht einschätzen.
Zusammenfassend lässt sich sagen, dass Barrierefreiheit scheinbar aufgrund seiner umfangreichen Definition sehr schwer zu messen ist und in Österreich vor allem in qualitativen Studien erforscht wird. Somit ist die Datenlange zu dieser Thematik ebenso nicht besonders umfangreich. Im Großen und Ganzen scheint es jedoch, ausgehend von der bestehenden Datenlage, bezüglich der gesetzlich vorgeschriebenen Barrierefreiheit im öffentlichen Raum noch großen Aufholbedarf zu geben.
Warum Väter nicht in Karenz gehen…und Kindererziehung (immer noch) Frauensache ist
Seit 1989 können Väter in Österreich in Karenz gehen. Doch Studien zeigen, wie ungleich die Kinderbetreuung in Jung-Familien dennoch hierzulande aufgeteilt ist: Nur jeder fünfte Vater nimmt Karenzzeit in Anspruch. Eine Analyse über Rollenbilder und geschlechtsspezifische Unterschiede in der Elternzeit.
Wien, Österreich. Als junges Elternpaar steht man vor vielen Herausforderungen und vor allem der Frage, wie sich die Zeit mit dem Kind mit dem Beruf und der finanziellen Situation vereinbaren lässt. In Österreich gibt es für diesen Fall ein vielschichtiges Karenz-System. Bei der Karenz handelt es sich laut Mutterschutzgesetz (MSchG) und Väter-Karenzgesetz (VKG) um einen arbeitsrechtlichen Anspruch von unselbständig erwerbstätigen Eltern, sich gegenüber dem/der Arbeitgeber:in von der Arbeitsleistung freistellen zu lassen, ohne dabei Lohn bzw. Gehalt zu bekommen. Dieser Anspruch besteht längstens bis zum zweiten Geburtstag des Kindes. Damit ist jedoch nur die arbeitsrechtliche Seite gedeckt. Um in dieser Zeit auch finanziell abgesichert zu sein, gibt es seit 2002 das sogenannte Kinderbetreuungsgeld (KBG). Das KBG steht allen Eltern nach der Geburt des Kindes zu, unabhängig von einer zuvor ausgeübten Erwerbstätigkeit.
Wer das KBG in Anspruch nimmt bzw. wie sich Kinderbetreuung im weiteren Sinne auf die Geschlechter aufteilt, zeigt das Wiedereinstiegsmonitoring 2021 der L&R-Sozialforschung, im Auftrag und in Zusammenarbeit mit der Arbeiterkammer Wien (AK Wien). Analysiert und ausgewertet wurden die Daten von 760.897 Personen, die zwischen 2006 und 2018 in Österreich Kinder bekommen haben (ausgenommen Selbstständige und Beamte). Die Ergebnisse gehen auseinander: Während sich die Zahl der männlichen KBG-Bezieher zwischen 2006 und 2018 mehr als verdoppelt hat, gehen Männer in acht von zehn Paaren weder in Karenz noch beziehen sie Kinderbetreuungsgeld. Damit ist auf Basis dieser Daten de facto jeder fünfte Vater an keinerlei Kinderbetreuung in den ersten Lebensjahren des Kindes beteiligt.
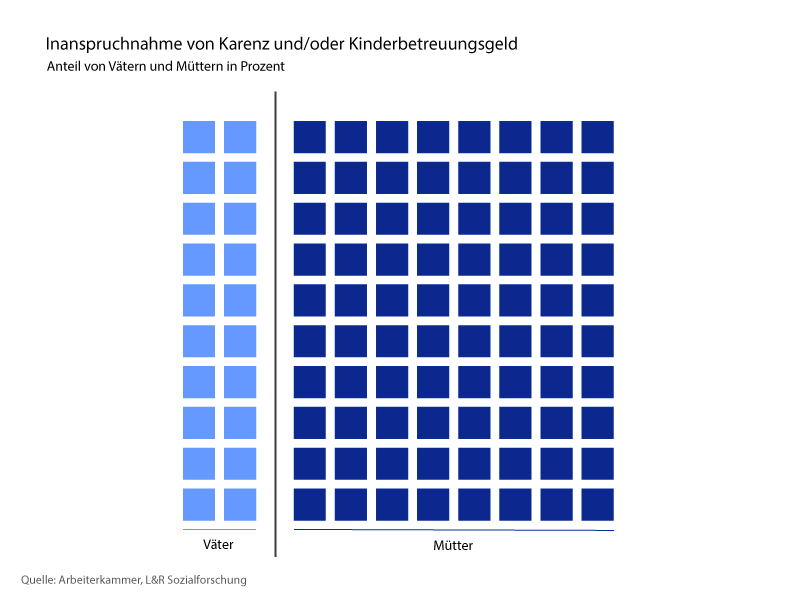
Im Detail nehmen auch die restlichen 20 Prozent der Väter nur eine kurze Variante in Anspruch: Zehn Prozent gehen nicht länger als drei Monate in Karenz, zwei Prozent drei bis sechs Monate und nur ein Prozent bleibt länger als ein halbes Jahr zuhause. Die restlichen sechs Prozent beziehen zwar Kinderbetreuungsgeld, unterbrechen aber ihre Erwerbstätigkeit nicht.
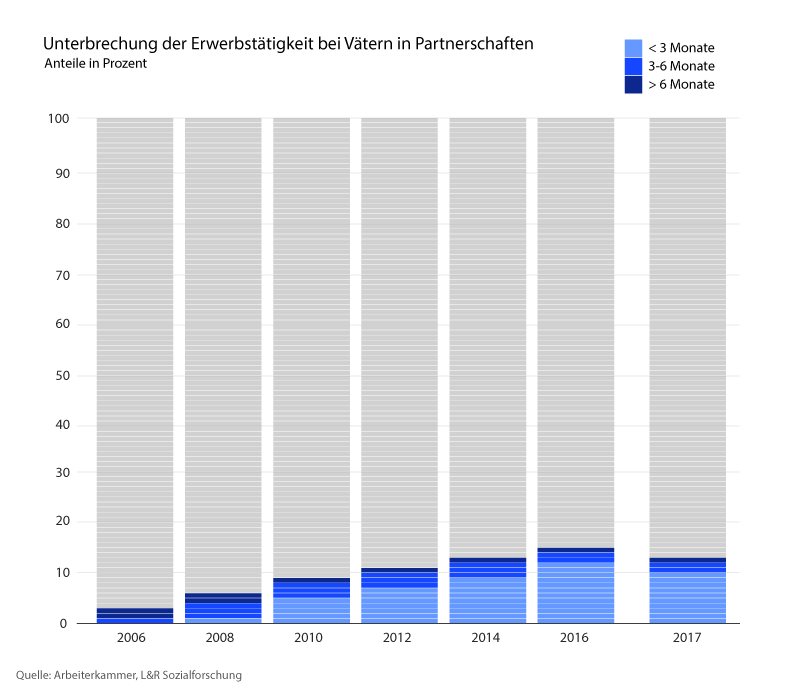
Warum ist das so?
Um dem fehlenden männlichen Anteil auf den Grund zu gehen, muss man sich die Entwicklung der letzten 20 Jahre, insbesondere die des KBG, genauer ansehen. Das Kinderbetreuungsgeld war seit seiner Einführung 2002 geprägt von zahlreichen Reformen. Bis 2008 gab es eine Pauschalvariante mit 30+6 Monaten: Ein Elternteil kann das KBG bis zur Vollendung des 30. Lebensmonats des Kindes beziehen. Wenn mit dem anderen Elternteil abgewechselt wird, kann das KBG sechs weitere Monate, also maximal bis zum dritten Geburtstag des Kindes, ausbezahlt werden. 2008 kamen zu der Variante die Modelle 20+4 und 15+3 Monate hinzu, 2010 eine weitere kurze Variante (12+2 Monate) und außerdem die Einführung eines einkommensabhängigen Kinderbetreuungsgeldes, um den mit der Geburt verbundenen Verdienstentfall für die Eltern möglichst gering zu halten und eine rasche Rückkehr ins Berufsleben zu ermöglichen. Nun standen den Eltern nach der Geburt also fünf Wahlmöglichkeiten zur Verfügung. 2017 trat nach einer weiteren Reform die bis heute geltende Regelung aus zwei Systemen in Kraft: Das einkommensabhängige KBG und die Pauschalvarianten neu zusammengefasst im sogenannten KBG-Konto.
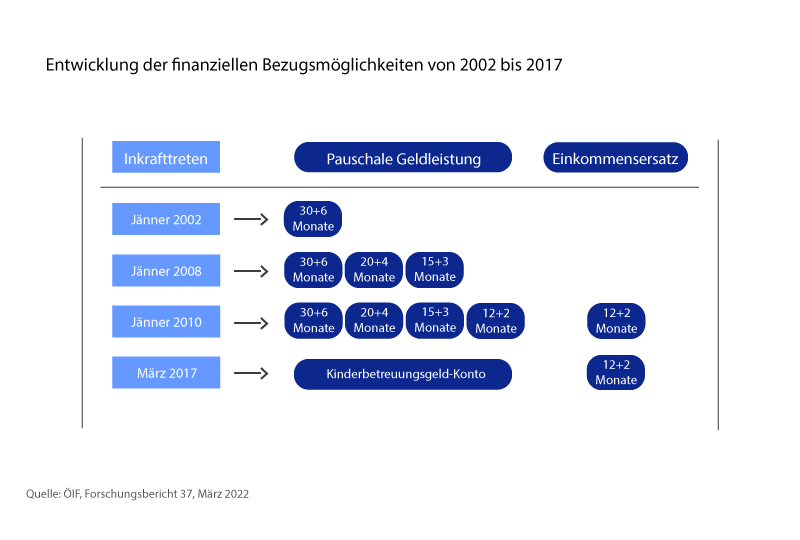
Das Ringen um die Väter
Um die berufliche Auszeit allgemein attraktiver zu machen und insbesondere den männlichen Anteil in der Karenzzeit zu erhöhen, wurde 2017 neben der KBG-Novelle auch der sogenannte Partnerschaftsbonus eingeführt: Haben beide Elternteile Kinderbetreuungsgeld mindestens im Ausmaß von 124 Tagen zu annähernd gleichen Teilen (50:50 bis 60:40) bezogen, so bekommen sie jeweils einen einmaligen Bonus in Höhe von 500 Euro ausbezahlt. Das Österreichische Institut für Familienforschung (ÖIF) an der Universität Wien hat sich in einer im März 2022 veröffentlichten Meta-Analyse unter anderem damit beschäftigt, welche Auswirkungen derartige Boni auf das KBG-Model im beobachteten Zeitraum 2018 bis inklusive 2021 haben. Das Ergebnis: Zwei Jahre nach Inkrafttreten des Partnerschaftsbonus wussten 40 Prozent der Befragten nicht, dass dieser überhaupt existiert.
Ein weiteres Mittel, um Väter bei der Kinderbetreuung in den Vordergrund zu rücken, sollte der Familienzeitbonus sein: Väter, die unmittelbar nach der Geburt ihre bisherige Erwerbstätigkeit für einen Monat unterbrechen, erhalten einen Familienzeitbonus in der Höhe von 700 Euro. Dieser Papamonat hat allerdings auch einen Nachteil: Bezieht der Vater zu einem späteren Zeitpunkt auch Kinderbetreuungsgeld, wird der Bonus vom KBG abgezogen. Das Wiedereinstiegsmonitoring 2021 der AK hat ergeben, dass die Zahl der männlichen Kinderbetreuungsgeld-Bezieher im letzten Beobachtungsjahr 2018 erstmals sogar rückläufig ist, was mit der Einführung des Familienzeitbonus zusammenhängen könnte. Nur wenige Väter nehmen außerdem sowohl den Papamonat als auch eine längere Karenzzeit in Anspruch.
Die Regierung hat diesbezüglich schon mehrfach betont, weitere Anpassungen im Gesetz vorzunehmen. Bisher ohne Antwort. Und schon bei der letzten Novelle 2017 bleibt offen, ob die derzeitige Lage auch tatsächlich ernst genommen wird. Das Sozialministerium (damals unter Minister Alois Stöger, SPÖ) beschreibt die Situation in einer Informationsbroschüre für Karenz folgendermaßen: „Immer mehr Männer wollen Zeit mit ihrem Nachwuchs verbringen, eine innigere Beziehung zu ihrem Kind aufbauen und intensiver an der Kindererziehung und -betreuung mitwirken. Die Vereinbarkeit von Familie und Beruf ist also längst kein reines ,Frauenthema‘ mehr.“ Doch damals wie heute zeigen die Meta-Analyse des ÖIF und das Wiedereinstiegsmonitoring 2021 der AK auf, dass das Problem nicht daran liegt, dass Väter weniger Zeit mit ihren Kindern verbringen wollen und deshalb weniger Karenz in Anspruch nehmen. Vielmehr geht es in den meisten Fällen um finanzielle Entscheidungen, die Frauen eher in die Karenz drängen als Männer.
Langfristige Nachteile für Frauen
Die Analyse der AK zeigt klar auf: Je höher das Einkommen des Vaters, desto kürzer fällt die Karenz aus. Und: Männer verdienen nach der Karenz langfristig sogar besser, während Frauen hingegen schlechter verdienen. Im Untersuchungszeitraum 2006 bis 2018 nehmen 54 Prozent der Frauen vor der Geburt des Kindes mindestens 2.000 Brutto/Monat ein, zwölf Jahre später sind es nur mehr 47 Prozent. Bei den Männern ist der Effekt umgekehrt: Vor der Geburt verdienen 66 Prozent der Männer mindestens 2.000 Brutto/Monat, zwölf Jahre später sind es 74 Prozent. Gründe für diesen Unterschied sind laut AK, dass Frauen deutlich länger durchgehend in Karenz gehen und danach zum Großteil teilzeitbeschäftigt sind, während Männer nach der Karenz fast ausschließlich einer Vollzeit-Beschäftigung nachgehen.
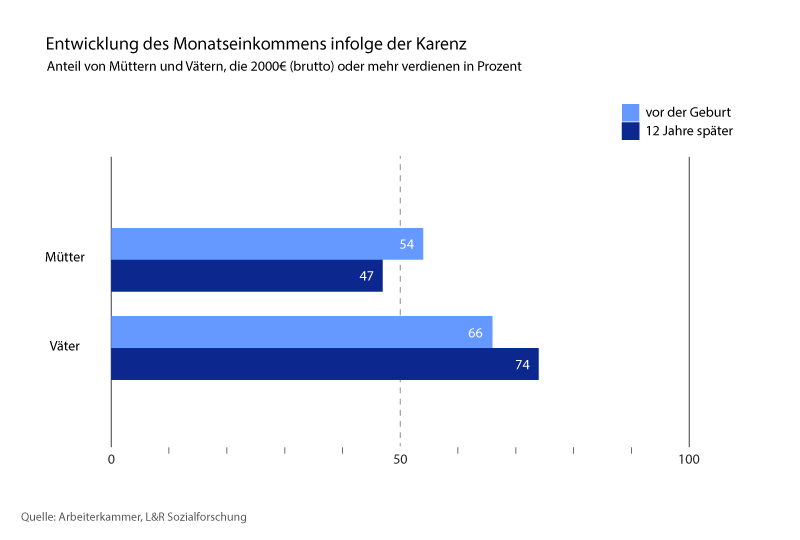
Auch die Wahl des Berufsfeldes schlägt in der Statistik auf: Väter, die im Sozialwesen arbeiten, nehmen am ehesten eine längere Karenzzeit. Wohingegen Väter mit einem Arbeitsplatz in der Finanz- und Versicherungsbranche, am Bau oder in der Waren-Produktion nur wenig wahrscheinlich in längere Karenzen gehen.
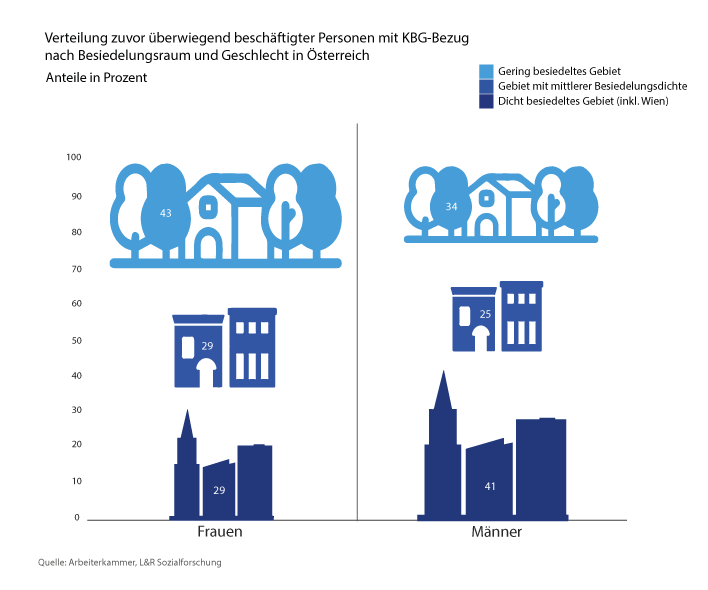
Darüber hinaus gibt es ein Stadt-Land-Gefälle: Väter mit Wohnsitz in der Stadt nehmen deutlich längere Karenzen in Anspruch als Väter in ländlichen Gebieten. Dies könnte laut AK mit traditionellen Rollenmustern zusammenhängen, die aufgrund fehlender Kinderbetreuung in manchen ländlichen Regionen verstärkt werden. Im gesamt-österreichischen Vergleich aller Personen, die KBG beziehen und zuvor erwerbstätig waren, lassen sich geschlechtsspezifische Unterschiede erkennen: Frauen finden sich häufiger im ländlichen Raum als in mittelgroßen Besiedelungsräumen (Städte und Vororte) und urbanen Zentren (zum Beispiel Wien). So waren im Jahr 2018 rund 43 Prozent der Frauen in ländlichen Gebieten beheimatet und jeweils 29 Prozent in Städten/Vororten und urbanen Zentren. Männer hingegen sind häufiger in urbanen Räumen zuhause: Im Jahr 2018 waren dies 41 Prozent. Ein Viertel aller vor KBG-Bezug überwiegend beschäftigter Männer hatten ihren Wohnsitz in Städten/Vororten und 34 Prozent im ländlichen Raum.
Und jetzt?
ÖIF und AK sehen Handlungsbedarf auf mehreren Ebenen: Die Väterbeteiligung gesetzlich zu regeln, wie dies zum Beispiel in Island der Fall ist, wäre eine Möglichkeit. Im isländischen Karenzmodell sind drei Monate für die Mutter vorgesehen, drei für den Vater und drei stehen zur freien Wahl. Jene Monate, die nicht in Anspruch genommen werden, verfallen. Der Anteil der Väter in Karenz ist seit der Einführung von 30 Prozent auf 90 Prozent gestiegen. Eine gesetzliche Änderung, aber auch Anreize und Förderungen auf Seite von Unternehmen und Arbeitgeber:innen hätten positive Auswirkungen auf traditionelle Rollenbilder und einen Kulturwandel zur Folge.
Wie die Analysen zeigen, wäre ein weiterer, einfacher Schritt die Auszahlung des Familienzeitbonus, ohne dabei im Nachhinein das KBG gekürzt zu bekommen. Es bedarf außerdem mehr Aufklärungs- und Öffentlichkeitsarbeit in Bezug auf die einzelnen KBG-Modelle und Boni. Und der ÖIF weist darauf hin, dass die Karenz als arbeitsrechtliche Rahmenbedingung für einen Teil der Bezieher:innen Ausschlag darüber gibt, welche KBG-Variante sie wählen. Es wäre in diesem Sinne, Karenz und KBG, die jeweils getrennt voneinander abgewickelt werden (Karenz seitens Arbeitgeber:in, KBG seitens Krankenversicherungsträger), zusammenzuführen und dementsprechend zu adaptieren.
Test – breite Datawrappergrafik
Hier ein Test – Wechseln auf „TEXT“ Editormodus.
Einstellung im Datawrapper:
- responsiver iframe beim Einbettcode
Nachlese Datenjournalismus Kurs an der FH Wien im Wintersemester 2020/21
Zum Ende des Wintersemesters 2020/21 ein kleiner Rückblick auf meinen Kurs „Datenjournalismus“ an der FH Wien, zwei besondere Aspekte möchte ich hervorheben:
1) Datenjournalismus und die Corona Krise
Das zentrale Thema gerade auch aus datenjournalistischer Sicht war natürlich die Corona-Krise, die uns in vielen Aspekten beschäftigte:
- viele bemerkenswerte Visualisierungen
- der Omnipräsenz von Zahlen
- der heiligen Gral der Vorhersage der Entwicklung des Infektionsgeschehens
- der globale Crashkurs im Verständnis von exponentiellem Wachstum
- die Probleme mit der Verfügbarkeit von verlässlichen und vergleichbaren Daten (besonders in AT)
- der Zweifel an der Glaubwürdigkeit von datenbasierten Fakten („everything can become polarized“)
2) Herausragende Arbeiten von Studierenden
- Die Sustainable Development Goals (SDG) in Österreich – von Emil Biller
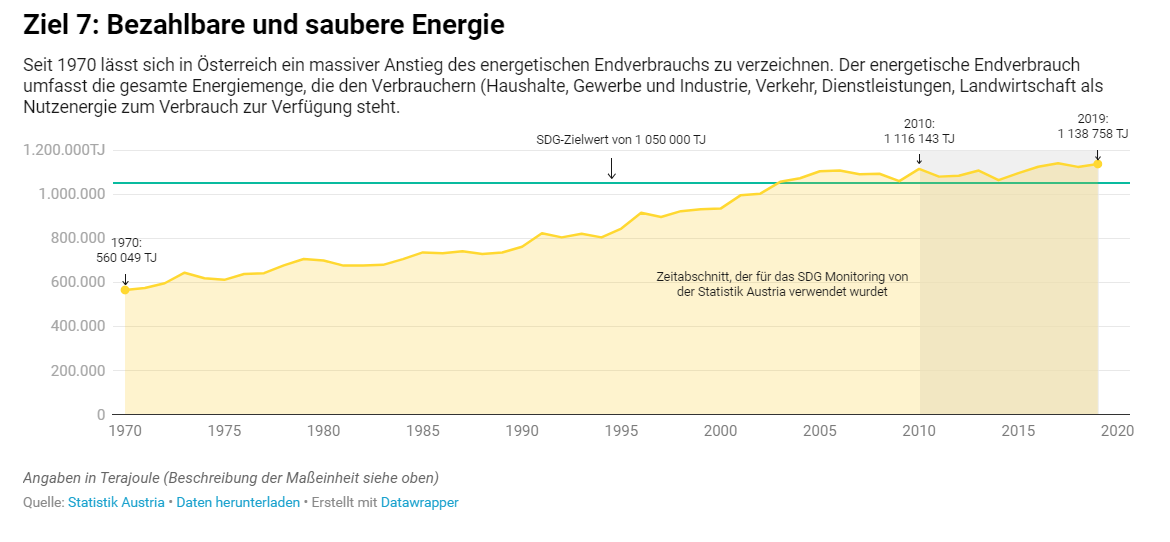 Eine umfassende Darstellung der SDG-Situation in Österreich
Eine umfassende Darstellung der SDG-Situation in Österreich - „Der ist schwul und will es nur nicht zugeben“ – von Hannah Horsten
 Kreativ umgesetzte Darstellung des Themas Bekenntnis zur Bisexualität in Europa
Kreativ umgesetzte Darstellung des Themas Bekenntnis zur Bisexualität in Europa - Teilzeit und Altersarmut: Frauen am österreichischen Arbeitsmarkt – von Maëlle Nausner
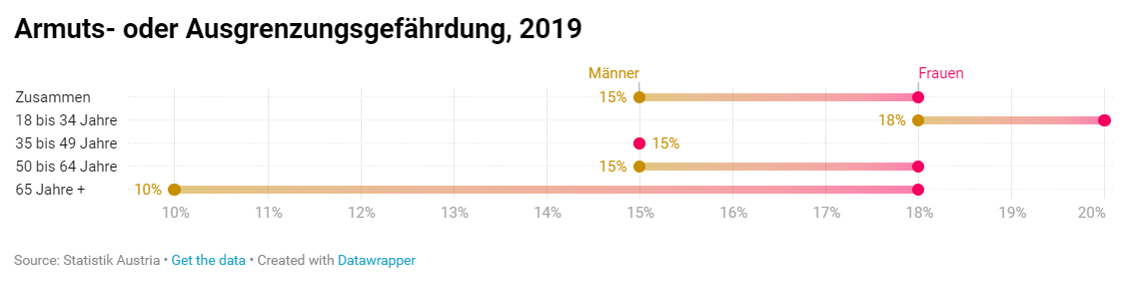 Vielschichtige Untersuchung des Zusammenhangs zwischen Geschlecht, Alter und Armutsgefährdung.
Vielschichtige Untersuchung des Zusammenhangs zwischen Geschlecht, Alter und Armutsgefährdung. - Erwartet Österreich ein Ärzt*innenmangel? – von Emilia Garbsch
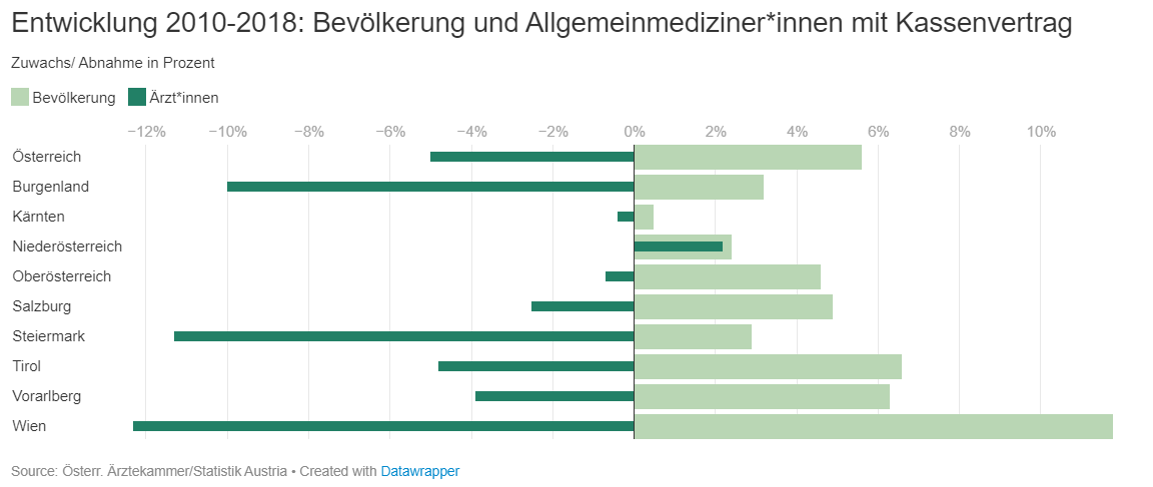
Umfassende Analyse des Themas Ärztemangel (Altersstruktur, regionale Unterschiede, Verhältnis Kassen- zu Privatverträge)
„Der ist schwul und will es nur nicht zugeben“
Warum outen sich so wenige als bisexuell?
In den letzten Jahren hat sich merkbar einiges getan in Sachen Offenheit gegenüber der LGBTQ+ Community (Lesbian, Gay, Bisexuall, Transgender, Queer). Wenn im Juni der sogenannte „Pride Month“ erneut anbricht, werden wieder Colaflaschen und Straßenbahnen mit Regenbogenflaggen geschmückt und in den sozialen Netzwerken viel gute und wichtige Aufklärungsarbeit geleistet. Aber so „trendy“ wie es hierdurch oftmals wirkt ist die Thematik gar nicht. Immer noch geben die meisten Personen, die nicht heterosexuell sind, an, nicht offen dazu zu stehen. Insbesondere bisexuelle Menschen scheinen mehrheitlich ungeoutet zu sein.
Coming out of the closet
Dieser Terminus beschreibt im Englischen, was im Deutschen meist schlicht unter „Coming-out“ bekannt ist. Hiermit ist jener Schritt gemeint, den LGBTQ+ Personen in einer heteronormativen Gesellschaft, also einer Gesellschaft, welche Heterosexualität als Norm darstellt, gehen müssen, damit das Umfeld oder die Öffentlichkeit über die sexuelle Orientierung beziehungsweise die Geschlechtsidentität bescheid weiß. Da unsere Gesellschaft – wie bereits erwähnt – heteronormativ ist, gehen die meisten Personen, die man kennelernt, vorerst von einer heterosexuellen Orientierung aus. Es ist also durchaus ein Privileg, sich als heterosexuelle Person nicht immer wieder aufs neue positionieren oder erklären zu müssen.
Der Schritt des Coming-outs ist für viele Personen nicht leicht – ebenso bleibt es im Laufe eines Lebens selbstverständlich nicht bei einem einzigen Coming-out. Man kann beispielweise im Freundeskreis geoutet sein, vor den Eltern jedoch nicht. Oder in der Verwandtschaft schon, aber nicht bei der Arbeit. Da sich der Begriff also ein wenig schwammig darstellt, wurden bei dem FRA LGBTI Survey – eine Befragung von der Agentur der europäischen Union für Grundrechte, Personen zu ihrer allgemeinen Offenheit mit ihrer sexuellen Orientierung befragt. Im Folgenden können nun die Schränke (closets) geöffnet werden, um den Anteil der LGB Personen zu sehen, der sagt sie gehen „sehr offen mit ihrer sexuellen Orientierung“ um. Lesbisch, Schwul oder Bisexuell sind neben Heterosexuell jedoch nicht die einzigen, weiteren Orientierungen. Es gibt auch Menschen die sich als Pansexuell (sexuell und emotional hingezogen zu Menschen jeder Geschlechtsidentiät) oder Asexuell (kein oder kaum sexuelles Interesse) identifizieren. Diese Personengruppen wurden jedoch in dem vorliegenden Datensatz nicht befragt.
Im folgenden sind die Ergebnisse für Österreich abgebildet.
Durch wischen auf die Schranktür und wieder heraus wird sichtbar, wie offen mit der eigenen sexuellen Orientierung umgegangen wird. Mit dem Smartphone online? -> Tippe auf die obere Ecke.
50% der sich als lesbisch identifizierenden Frauen in Österreich sagen sie gehen sehr offen damit um. Das ist im EU-Schnitt sehr hoch. Höher ist dieser Anteil nur in den Niederlanden (59%), in Schweden (64%) und in Dänemark (69%).
37% der schwulen Österreicher stimmen der Aussage zu, dass sie mit ihrer sexuellen Orientierung sehr offen umgehen. Das ist immerhin über dem EU-Durchschnitt, welcher bei 34% liegt.
Lediglich 16% der bisexuellen Männer in Österreich gaben an, damit sehr offen umzugehen. Das mag wenig klingen, es sind jedoch im EU-Schnitt sehr viele. Vor Österreich sind nur noch Belgien und Dänemark mit jeweils 17%.
Bisexuelle Frauen gehen in Österreich sogar noch seltener offen mit ihrer sexuellen Orientierung um als bisexuelle Männer. Hierbei liegt Österreich jedoch nur knapp über dem EU-Schnitt. Tendenziell gehen Frauen in Europa offener hiermit um als Männer. Während bei Männern über die Hälfte nie darüber spricht, ist es bei den Frauen in etwa ein Drittel.
Auffällig hierbei ist der große Unterschied. Während die Hälfte aller lesbischen Frauen in Österreich offen dazu steht, Mitglied der LGBTQ+ Community zu sein, ist es bei den bisexuellen Frauen knapp ein Siebtel. Auch im EU Vergleich sind bisexuelle Menschen bei weitem nicht so offen bei der Thematik wie homosexuelle.
Woher kommen diese Unterschiede?
Insbesondere bisexuelle Männer sind laut diesen Umfragewerten sehr zurückhaltend was ihre Sexualität betrifft. In Osteuropa sind es in keinem Land mehr als 3%. Ein Grund hierfür könnte die politische Lage sein. In Polen beispielweise gibt es seit dem Jahr 2019 sogenannte „LGBT-ideologiefreie Zonen“. Auch wenn es sich bei Lesben, Schwulen, Bisexuellen und Transpersonen nicht um Ideologien handelt und diese Zonen juristisch keine Folgen haben sind sie durchaus ein deutliches Signal zur Ausgrenzung von Personen aus der Community. Trotz der feindlichen Haltung der Regierung gegenüber LGBT Personen, sind die Zahlen der Schwulen und Lesben, die in Polen offen zu ihrer Sexualität stehen (9% und 11%) deutlich höher als die der bisexuellen Frauen und Männer (2% und 1%). Woher könnte das kommen?
Ein möglicher Grund könnte sein, dass bisexuelle Personen nicht gleichermaßen auf ein Outing angewiesen sind wie homosexuelle Personen. Während Lesben und Schwule sich gewissermaßen outen müssen, um sexuelle Bedürfnisse frei ausleben zu können, können Bisexuelle dies auch (oder zumindest teilweise) ohne Outing – gewissermaßen unter dem Deckmantel der Heteronormativität.
Auch ohne Angst vor politischer Feindseeligkeit ist, wie im ersten Absatz beschrieben, ein Outing meist ein unangenehmer Schritt. Man entblöst sich, von der, durch die Gesellschaft festgelegte, Norm abzuweichen. Auch in scheinbar politisch offeneren Ländern ist dies ein Schritt der immer mit einem Kampf mit Vorurteilen zusammenhängt. Wenn man in einer gegengeschlechtlichen Beziehung ist, wird eventuell auch von dem Umfeld der Kontext des Outings nicht ganz verstanden.
60% der in Österreich lebenden, bisexuellen Männer sprechen im Gegensatz nie offen über ihre Bisexualität und werden somit vermutlich, fälschlicherweise, vom großteil ihres Umfelds als heterosexuell wahrgenommen.
„Weil du nicht homo oder hetero wirst, sondern bi bleibst.“
Zwei Interviews
Den besten Einblick in die Lebensrealitäten von bisexuellen Personen bekommt man natürlich von ihnen selbst. Melissa (24) und Hanna (22) haben im Folgenden einige Fragen zum Thema Outing beantwortet. Die Antworten überschneiden sich teilweise sehr stark – was an dem ähnlichen Alter und den ähnlichen Lebensumständen liegen mag – eventuell zeigt es jedoch auch eine ähnliche Wahrnehmung der Gesellschaft auf.
Hast du das Gefühl, dass ein Outing als nicht heterosexuell in unserer Gesellschaft notwen dig ist?
dig ist?

Melissa: Ich denke schon, dass man sich in unserer Gesellschaft noch outen muss. Leider. Wir haben zwar vielleicht das Gefühl, dass ein Outing nicht mehr notwendig ist – weil wir jedes Jahr hunderte Regenbogen-Fahnen in Schaufenstern und der Werbung sehen, weil wir auf die Pride-Parade gehen, weil die Popkultur so divers wie noch nie ist (mit Figuren wie Janelle Monae, Kehlani, Miley Cyrus, Frank Ocean und und und) und wir auf Netflix und Amazon Prime immer mehr Serien oder Filme mit dem Label ‚LGBTIQ‘ sehen. Und diese Veränderung ist extrem wichtig, weil es dadurch mehr Sichtbarkeit für uns gibt. Aber das heißt nicht, dass wir nicht weiterhin in einer heteronormativ
en Gesellschaft leben, wo die Liebesbeziehung zwischen Mann und Frau das ‚Normale‘ ist und alles andere eine ‚Abweichung‘ der Norm ist.
Hanna: Ich finde, dass es eine sehr individuelle Frage ist, ob jemand für sich überhaupt ein Outing braucht – die nicht pauschal beantwortet werden kann. Das „Outing“ ist ein zweischneidiges Schwert, da Sichtbarkeit und Repräsentation zwar wichtig sind, andererseits jedoch ein starkes Hervorheben der nicht-heterosexuellen Identität, die ‚Andersheit‘ wieder stark unterstreicht. Folglich ist ein Outing in unserer Gesellschaft eine Positionierung zum ‚Anderssein‘.

Was verstehst du überhaupt unter dem Begriff Outing?
Melissa: Sich outen zu müssen heißt für mich sich brandmarken zu müssen – für die Person, die man ist. Zu sagen: Hey, ich bin anders als ihr, weil ich anders liebe. Ganz ohne Outing kommt man aber nicht aus, weil man sonst weiterhin mit simplen Fragen wie ‚Hast du einen Freund?‘ getriggert wird. Man muss sich also als ‚anders‘ deklarieren, damit man nicht mehr in die Hetero-Kategorie gesteckt wird. Und in dem Moment, wo ich sage, „ich bin anders“, in dem Moment oute ich mich.
Hanna: Für mich persönlich ist Outing ein Informieren und ein zu seiner eigenen Sexualität oder Genderidentität stehen.
Hast du persönlich das Gefühl, dass es bisexuellen Personen bei einem Outing schwerer gemacht wird? Oder leichter?
Melissa: Es ist auf gewisse Art und Weise leichter und schwieriger gleichzeitig, weil man als bisexuelle Person ganz anders wahrgenommen wird. Leichter ist es, weil man als bisexuelle Person noch mit einem Fuß in der Hetero-Gesellschaft steckt und ja nur „halb anders“ ist, sozusagen. Genau das macht es aber auch schwerer, weil man in seiner Sexualität oft nicht ernst genommen wird. Bei bisexuellen Männern heißt es oft: „Der ist schwul und will es nur nicht zugeben“, Frauen bekommen oft zu hören: „Das ist eine Phase, die geht wieder vorbei.“ Dass Bisexualität aber eine legitime Orientierung ist, genauso legitim wie Hetero oder Homo, verstehen viele immer noch nicht.
Hanna: Ich habe das Gefühl, dass man etwas weniger ernst genommen wird, als eine homosexuelle Person, die sich outet, da es oft als eine Art der „Transition“ zum Lesbisch- oder Schwulsein gesehen wird. Auch von Seiten der LGBTQ+ Community wird man des Öfteren nicht ganz akzeptiert, da es so wirkt, als ob man sich „nicht zwischen zwei Seiten entscheiden“ könne oder „eine Phase“ durchlaufe. Auch wird man als bisexuelle Frau vor allem von heterosexuellen Männern öfters fetischisiert, mit Einladungen oder Erwartungen auf einen Dreier.
Welche Personen in deinem Umfeld wissen von deiner Bisexualität? Ist es dir wichtig, dass sie das Wissen?
Melissa: Ich habe seit drei Jahren eine Partnerin, was jeder weiß, der mich etwas besser kennt. Das heißt Leute in meinem engeren Umfeld wissen, dass ich bi bin. Davor wusste das aber niemand, weil ich es nicht ausgesprochen habe. Das ist so ein Ding mit Bisexualität: Solange du Personen datest oder eine*n Partner*in hast, die nicht dasselbe Geschlecht haben wie du selbst, würde niemand denken, dass du bi bist. Du wirst als hetero gelesen. Sobald du eine*n Partner*in hast oder jemanden datest, der oder die dasselbe Geschlecht hat wie du, wirst du als homo gelesen.
Das macht es kompliziert, weil du nicht homo oder hetero wirst, sondern bi bleibst. Ich glaube mir ist es weniger wichtig, dass die Leute wissen, dass ich bi bin, als dass sie mich einfach so respektieren wie ich bin. Und das geht schneller und ist leichter, wenn ich sag ‚ich bin bi‘, als wenn ich sag ‚Ich finde Menschen attraktiv, weil sie eine gewisse Ausstrahlung haben – und nicht, weil sie ein gewisses Geschlecht haben‘. Bi ist eben ein Code-Wort, wo jeder weiß, wo du stehst. Das Label an sich bzw. die Tatsache, dass man sich überhaupt labeln muss – naja, das hilft den Menschen eben dich zu kategorisieren. Anders wäre es denke ich, wenn ich einen Partner hätte. Dann würde es mich wahrscheinlich verletzen, wenn mich Menschen plötzlich als hetero lesen würden und es wäre mir wichtiger, dass Menschen wissen, ich bin bi.Hanna: Es wissen zum Großteil meine Uni-Kolleg*innen, meine Schwester und mein Partner. Es ist mir schon wichtig, dass sie es wissen, da es doch ein Teil meines Lebens und meiner Persönlichkeit ist.
Gibt es Personen, denen du bewusst nicht von deiner Bisexualität erzählst? Warum?
Melissa: Ja, einem Großteil meiner Familie, weil ich weiß, wie sie reagieren würden (Surprise, nicht so gut). Das ist aber nicht so schlimm für mich, weil sich der Kontakt in Grenzen hält und ich es daher nicht für unbedingt notwendig halte. Da geht’s mir vor allem um Selbstschutz.
Hanna: Meine Verwandtschaft weiß es nicht, weil ich weiß, dass ich da bei manchen auf Unverständnis stoßen würde. Außerdem ist es mir bei meiner Verwandtschaft nicht so wichtig, dass sie davon wissen wie bei Freund*innen, mit denen ich ein engeres Verhältnis habe.
Hast du bereits negative Reaktionen erhalten, nachdem du Personen von deiner Bisexualität erzählt hast? Wenn ja – inwiefern?
Melissa: Ja, von meiner Mutter. Ich glaube allerdings, dass das viel mehr eine Reaktion auf die Tatsache war, dass ich eine Partnerin hatte, als darauf, dass ich bisexuell bin. Da ist wieder dieses Ding: Bisexualität an sich kann man verstecken, sie wird erst sichtbar, wenn man Menschen des gleichen Geschlechts datet. Und solange sie nicht ‚sichtbar‘ wird (also die ‚abweichenden‘, Homo-Tendenzen sichtbar werden), wird sie oft und gerne ignoriert oder leichter akzeptiert. Ich hatte kein einfaches Outing, weil es für meine Mutter anfangs sehr schwierig war und völlige Unverständnis und Panik geherrscht hat. Das hat sich nach einer Zeit und viel Schmerz aber beruhigt, weil sie sich auch damit auseinandergesetzt hat, woher diese Unverständnis in ihr kommt. Ich bin ihr deswegen auch nicht böse – obwohl es sehr schwer für mich war – weil ich eben auch weiß, wie schwer es für sie war.
Ansonsten hatte ich keine schlechten Erfahrungen.Hanna: In meinem näheren Umfeld zum Glück nicht, nur bei manchen unbekannten, oben genannten, heterosexuellen Männern. Da kamen besagte Bemerkungen oder Blicke, wo ich mir wünschen würde, dass man sich informiert oder zumindest nachfragt. Außerdem kam es schon vor, dass meine Bisexualität in Frage gestellt wurde, da ich bisher nur männliche Partner hatte.
Conclusio
Wie können wir alle, als Teil der Gesellschaft, also bisexuellen Personen eine Plattform für mehr Offenheit bieten? In erster Linie in dem jede*r sich über den Umstand der Heteronormativität bewusst wird. Fragen wie „Hast du einen Freund?“ an Frauen oder im Gegenzug „Hast du eine Freundin?“ bei Männern projizieren automatisch ein eigene kreiertes, heterosexuelles Bild auf das Gegenüber, das eventuell mit der Realität nicht übereinstimmt. Außerdem sollte Menschen, die zu ihrer Bisexualität stehen, diese nicht abgesprochen werden oder als „Phase“ abgestempelt werden. Selbst wenn es eine Phase sein sollte kann alleine die Person selbst das für sich feststellen und nicht das Umfeld. Denn die Bisexualität hört ja nicht auf, bloß weil jemand in einer heterosexuellen Beziehung ist.
Text und Illustrationen: Hannah Horsten – Daten: FRA LGBTI Survey